伪逆法
分类器,是一切模式识别的基础,不管你想识别多么复杂的东西,待识别对象有多少类,你都必须要用上分类器,而不管分类器多么的复杂,归根结底,都是二分类的分类器,而二分类问题,最基础的就是线性分类器。。
虽然线性分类器在实用中不会被用上,但是许多研究的基础都是从线性分类器开始的,以前说的那个Adaboost,一个分类器可以由n多个线性分类器加权级联起来,SVM即便引进了核函数,通过把低维映射到高维空间使之线性可分,但是其研究基础还是线性分类器【过阵子良心发现了就补一篇SVM的吧。。】,神经网络每个神经元是什么?还是线性分类器。
以前被Adaboost和神经网络的那种思维模式误导了,比如说,在Adaboost算法中寻找来级联的弱线性分类器是怎么找的,扫面整个分类器集合找到目前为止最好用的一个弱分类器。神经网络中的神经元的权值是怎么算的?还不是要训练,修正?以至于我决定的,线性二分类问题找到的一个最简单的分类器必须要迭代训练【这里不是说要找最优分类器】。
最近上课老师提到了一个伪逆法,由于我睡过去了,没听清楚,回来上网查了一下,发现这个东西好像还挺好用的~至少思想值得学习!!
伪逆法思想是基于最小二乘的,假如说我们有一堆数据,数据量为N,每个数据向量为m维的,表示如下:
X原始数据=
\(\left(\begin{array}{cccc}x_{11} & x_{12} & … & x_{1m} \\x_{21} & x_{22} & … & x_{2m} \\&&…&\\x_{N1} & x_{N2} & … & x_{Nm} \end{array}\right)\)
| x11 | x12 | … | x1m |
| x21 | x22 | … | x2m |
| ┇ | |||
|---|---|---|---|
| xN1 | xN2 | … | xNm |
然后我们在左边增加一列1,变成X:
\(\left(\begin{array}{ccccc}1 & x_{11} & x_{12} & … & x_{1m} \\1 & x_{21} & x_{22} & … & x_{2m} \\&&…&&\\1 & x_{N1} & x_{N2} & … & x_{Nm} \end{array}\right)\)
目标期望输出Y= (y1,y2,…yN)T;
yi=1表示第i个数据样本属于第一类,yi=-1表示属于第二类;
现在计算出来的决策平面为W=(w0,w1,w2,wm)T;
现在的输出d = XW;
对于第k个样本的输出dk等于
dk=w0+xk1w1+xk2w2+…+xkmwm=WTXk
那么输出的误差就是:|dk-yk|
所有数据的误差的平方和就是:
\(e=\sum|d_k-y_k|=\sum|W^TX_k-y_k|=(Y-XW)^T(Y-XW)\)
求导,令e关于W的导数为0,看到了吧,这就是最小二乘法嘛。。
\(\dfrac{\partial e}{\partial W}=-2X^T(Y-XW)=0\)
\(=>X^TY=X^TXW\)
\(=>W=(X^TX)^{-1}X^TY\)
显然,XTX不可逆时该方法就跪了,但是这种情况不常见。。
然后,看了一下老师给的那一份代码,我发现其实计算上可以有两种不同的方法,但是最后算出来的结果是一样的,老师的代码计算如下:
首先有原始数据矩阵如下:
\(\left(\begin{array}{ccccc}y_1 & x_{11} & x_{12} & … & x_{1m} \\y_2 & x_{21} & x_{22} & … & x_{2m} \\&&…&&\\y_N & x_{N1} & x_{N2} & … & x_{Nm} \end{array}\right)\)
yi是目标输出结果,也就是归属的类别,为1或-1。
然后,把上面那个矩阵中yi=-1的那一行中所有的x全部取相反数,假设y2=-1,那么上面矩阵就变成:
\(\left(\begin{array}{ccccc}y_1 & x_{11} & x_{12} & … & x_{1m} \\y_2 & -x_{21} & -x_{22} & … & -x_{2m} \\&&…&&\\y_N & x_{N1} & x_{N2} & … & x_{Nm} \end{array}\right)\)
然后目标输出就是b = [1 1 1 1 … 1],N个1组成的的,
计算:
W = (XTX)-1XTb
结果和上一种方法算出来一样的。【为什么一样,自己推去~】
老师的程序里面表示,上面的b可以变成任何东西,假如在matlab中b变成ones(N,1).*rand(N,1),相对于第一种方法,如果你想明白两种方法为什么相等的话,那就知道只要把第一种方法里面的Y变成Y.*rand(N,1)就可以了。
把b改变一下值,也可以算出一个W来,而且都是比较不错的分类器,但是后来有个人给出了个HoKashyap算法(也可能是两个人),通过不断地修正b的值来取得更好的分类器,算法如下:
- 随机给W赋值,假设为[1 1 1]T;
- b也随便赋值吧
- 计算误差e = XW-b;
- 更新b:b =b+0.5*( e+|e| );,也就是把b对应e中为负数的位置的数变成0,其余不变。
- 更新W:W = (XTX)-1XTb;
- 如果e每个元素都小于0,说明线性不可分;
- 如果e每个元素都为0,说明线性可分;
- 否则,跳回步骤3
这个算法厉害吧,还可以判断是否线性可分!!!
给几个结果图吧,两个两个一组,分别是用普通伪逆法和HK伪逆法的结果:
伪逆法1:

伪逆法HK1:
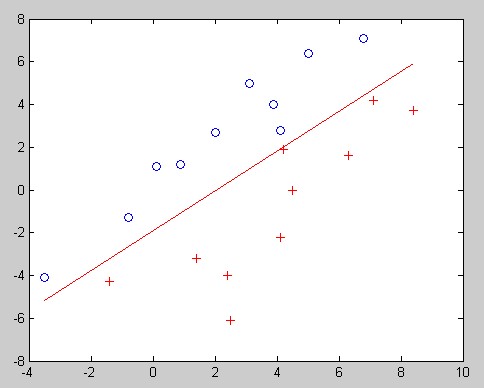 伪逆法2:
伪逆法2:
 伪逆法HK2:
伪逆法HK2:
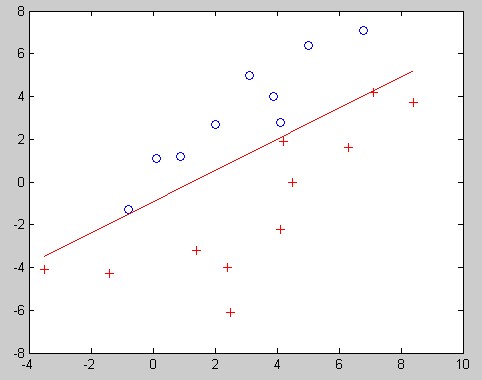 伪逆法线性不可分:
伪逆法线性不可分:
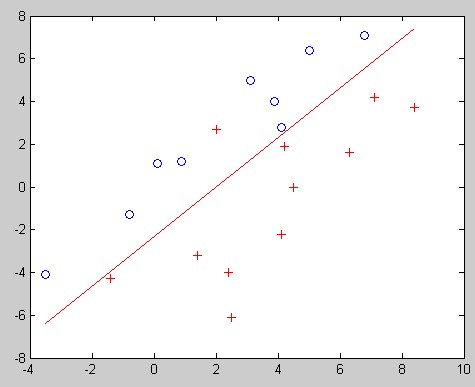 伪逆法HK线性不可分:
伪逆法HK线性不可分:
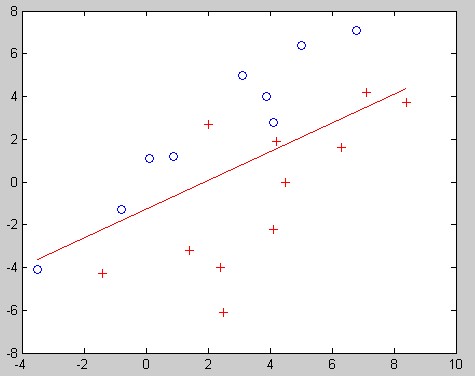
HK算法感觉上好像比普通伪逆法好一些,最重要的是,他可以判断是否线性可分,但是咧,知道是否线性可分很重要么??哈哈。。。
下面是代码,如果你运行一下的话,就知道,HK法不是一般的慢。。。
function PsudoInverse()
clc;
close all;
data=[0.1, 1.1, 1;
6.8, 7.1, 1;
-3.5,-4.1,1;
2.0, 2.7, 1;
4.1, 2.8, 1;
3.1, 5.0, 1;
-0.8,-1.3,1;
0.9, 1.2, 1;
5.0, 6.4, 1;
3.9, 4.0, 1;
7.1, 4.2, -1;
-1.4,-4.3,-1;
4.5, 0.0, -1;
6.3, 1.6, -1;
4.2, 1.9, -1;
1.4 -3.2, -1;
2.4, -4.0, -1;
2.5, -6.1, -1;
8.4, 3.7, -1;
4.1, -2.2, -1];
M = size(data,1);
X = data(:,1:2);
Y = data(:,3);
X_pos = X(find(data(:,3)==1),:);
X_neg = X(find(data(:,3)==-1),:);
X_2 = [ones(M,1) X];
w = inv(X_2'*X_2)*X_2'*Y
line_x = [min(X(:,1)) max(X(:,1))];
line_y = -(w(1)+w(2)*line_x)/w(3);
plot(X_pos(:,1),X_pos(:,2),'bo',X_neg(:,1),X_neg(:,2),'r+',line_x,line_y,'r');
%第二种计算方法
data(find(data(:,3)==-1),1:2) = -data(find(data(:,3)==-1),1:2);
X3 = [data(:,3) data(:,1:2)];
Y = ones(M,1);
w2 = inv(X3'*X3)*X3'*Y;
line_y2 = -(w2(1)+w2(2)*line_x)/w2(3);
plot(line_x,line_y2,'b');
%HoKashyapAlgorithm改进
flag = 1;
w = [1 1 1]';
b = ones(M,1);
delta = 2;
while flag>0
e = X3*w-b;
b = b+0.5*delta*(e+abs(e));
w = inv(X3'*X3)*X3'*b;
figure(1);
line_y = -(w(1)+w(2)*line_x)/w(3);
plot(X_pos(:,1),X_pos(:,2),'bo',X_neg(:,1),X_neg(:,2),'r+',line_x,line_y,'r');
if max(e)< =0 %点集 X 不线性可分
flag = -1;
elseif max(abs(e))<0.001 %点集 X 线性可分
flag = -2;
end;
end
flag
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

二〇一二年就搞高大上的机器学习了,真幸福。