性别识别专题三——实例应用
好吧,专注填坑30年的我又回来了。。。
这次总算真的可以写一下性别识别这个东西了,因为性别识别是个目的,然后为了完成这个目的,需要多种算法手段来实现,所以这就是前面两个专题里面提到的PCA和线性分类器了。
好吧,不多说,直接开始介绍正题。【哦对了,这篇文章主要是写给对模式识别不怎么熟悉的人看的,所以大牛基本可以不要在这里浪费时间了。。反正就是PCA+LDA嘛,你们懂得~】首先,我们这里采用的性别识别的原材料是图片,而且不是大景观的图片,而是人头像,就像下图:

 接下来我们要做的就是,读取一张图片,因为是RGB三色图像(也有些训练数据是灰度图,为了方便说明,就假定全部都是RGB图片没有灰度图片吧。)我们就可以获得一个m×n×3的数据,把这个数据作为输入,送进我们的模型里面,理想的结果就是,我们的模型可以对男性输出1,女性输出-1,这就是我们想要的结果。
接下来我们要做的就是,读取一张图片,因为是RGB三色图像(也有些训练数据是灰度图,为了方便说明,就假定全部都是RGB图片没有灰度图片吧。)我们就可以获得一个m×n×3的数据,把这个数据作为输入,送进我们的模型里面,理想的结果就是,我们的模型可以对男性输出1,女性输出-1,这就是我们想要的结果。
说的简单,那要怎么得到这个中间的模型呢?那就要用到我们之前所说的PCA和线性分类器来训练了。
首先,我们读入的图片是m×n×3,但是一般都是277×277,或者292×292什么的,那么我们算一下就知道这个输入的待识别的东西的维数大约是280×280×3=235200,好大是吧,所以呢,一般做模式识别之前,都要先做数据的预处理,我们这边的预处理很简单就是采样降维:
预处理:
- 把图片采样,统一变成大小为m×n的大小,比如说,m=n=32
- 把图像灰度化,反正就是matlab里面的一句rgb2gray
- 把图片变成一个长度为m×n的一维列向量
预处理部分前两步是为了降低维数或者后期的计算量,你看一开始的235200维现在就变成了32×32×1=1024维了不是么?第三步是为了编程处理的方便,你想想啊,一张图是二维的,两张图想放在一起就是变成3维了不是么?现在每张图片都变成1024维的一个列向量表示,那不就很方便?为了方便理解,下面每做一步我都会强调一下现在数据的维数的,在明确一遍,现在每张图片都变成了mn×1的列向量了,第i个样本我们称之为Xi。
接下来,我们之前所说的PCA就可以用得上了,原因就是我们觉得1024维来表示一个图片还是太多了,如果可以用几十个数据来表示一整图片那就在理想不过了。或者再直观一点看,可能我上面的图都比较小,看的不是很清楚,就是每个图片周围都有一些头像以外的部分,这些部分大部分是蓝色的,不管男女老少,所以呢,在1024维里面有些数据是这些,但是这些数据对于识别完全不起作用,所以我们认为这种数据应该抛弃。
PCA:(假设我们训练的样本库的总量是N幅图片)
- 对于每个列向量样本,我们计算出所有样本的平均值,这个平均值自然也是一个mn×1的列向量,成为Avg
- 将每个样本都减去Avg,得到归一化样本,也就是说:Xnormi=Xi-Avg
- 将所有的归一化样本拼成一个mn×N的样本矩阵X。也就是说X的每一列就是一个样本列向量
- 按照PCA算法约定,计算这个样本矩阵X的协方差矩阵Q = XXT,Q的维数是mn×mn
- 计算Q的特征值(mn个数)和特征向量(mn个向量,每个向量是mn×1)。
- 将特征值从大大小排序
- 取最大的k个特征值他们对应的特征向量组成状态空间w1=mn×k
- 计算降维后的样本矩阵:Y=w1TX,Y是k×N
你看,经过PCA的计算,我们现在需要识别的东西就是Y,而Y代表的是N个样本,每个样本维数是k,而k是我们从mn个特征值中挑出的k个较大的特征值,所以k必然小于mn,而且,一般情况下,k是远小于mn,所以我们现在的维数大大降低了。
有些人对PCA的误解是从mn的的维数中挑出k个来,其实不是,是把一个mn的列向量通过w1这个变换(其实就是相乘),变成一个k维的数据,有个变化在里面,而不是直接筛选。
到现在为止,我们得到了代表了每个样本的一个列向量,维度是k,假设k=100吧,这完全不夸张。
那接下来呢?就是识别啦,用的就是我们之前讲的Fisher分类器,也就是说现在待识别的空间是k=100维的一个高维空间,我们需要找到一个100维的高维的“线”,将不同的样本对应的100维的“点”分开。
LDA:(法一,可以直接跳过)
- 分别计算男性样本和女性样本的平均值Avg1和Avg2,我们这里用的“每个样本”还是最开始的mn维的数据,所以得到的两个平均值样本也是mn×1维的。
- 将每个男性样本减去男性样本的平均值,女性的则减去女性样本的平均值,说白了就是得到男女两性的“类内归一化样本”。
- 将这些“类内归一化样本”拼成一个矩阵Xw,这个矩阵维数是mn×N。
- 我们构造另外一个矩阵Xb,这个矩阵维度是mn×N,每一列对应Xw中的一个样本,如果Xw的这一列是男性,那么Xb的这一列的值就是Avg1-Avg,如果这一列对应的是女性,那么Xb的这一列的值就是Avg2-Avg。
- 计算Sw=w1TXwXwTw1,所以Sw的维数是k×k。
- 计算Sb=w1TXbXbTw1,所以Sb的维数是k×k。
- 计算空间矩阵R = Sw-1Sb,R是k×k。
- 为了进一步降低识别空间的维数,对R再做一部分PCA,也就是计算出R的特征值和特征向量,挑出他们最大的p个特征值对应的特征向量,组成一个子状态空间w2,维数是k×p
- 融合子空间,得到最终的w=w1w2。
- 得到最后的识别列向量Y2=wTX,Y2是p×N维
我们这里相当于把维数一降再降,一开始的1024维讲到k=100维,现在再降到p维,而且,一般数据正常的话,这里的p都是1维,对,1维,什么概念,就是一个数!!我们现在可以用一个数来表示一幅图像了,当这个数大于某个值,就说明这幅图像是男的,小于某个值,就说明是女的,我们简直不能兴奋更多,因为难道你不觉得这很神奇么??
不过,在说最后的结果之前,我们还再讲另一个事情,就是上面的那个LDA,其实它对应的是我下面给出的代码的实现,完全对应,但是如果不是很了解算法,又是刚刚看了专题二的话,肯定不清楚上面那个LDA在干什么,为什么可以实现功能,那么我现在就给出上面那个算法一个等价的计算过程,这个就和我们之前讲的LDA完全对应上,不过怎么证明这两个等价,自己想去吧~
LDA:(法二)
- 分别计算男性样本和女性样本的平均值Avg1和Avg2,我们这里用的“每个样本”还是最开始的mn维的数据,所以得到的两个平均值样本也是mn×1维的。
- 将每个男性样本减去男性样本的平均值,女性的则减去女性样本的平均值,说白了就是得到男女两性的“类内归一化样本”。
- 将这些“类内归一化样本”拼成一个矩阵Xw,这个矩阵维数是mn×N。
- 计算Sw=w1TXwXwTw1,所以Sw的维数是k×k。
- 计算Y=w1TX,Y是k×N
- 计算Y对应男性部分的平均值AvgY1和女性部分的平均值AvgY2,也就是说,k×N的Y是全部样本N的PCA降维到k之后的值,现在算出男女性的Y的平均值,AvgY1和AvgY2维数是k×1.
- w=Sw-1(AvgY1-AvgY1),维数是k×1
- 待识别的样本矩阵就是wTY。
法二的话大家就懂了吧,其实只有在法一算出来的第二次PCA的结果取最大的1个特征值(也就是p=1)的情况下,这两种方法等价!
最后,既然我们算出来的是一个数,那么我们就把结果画出来吧~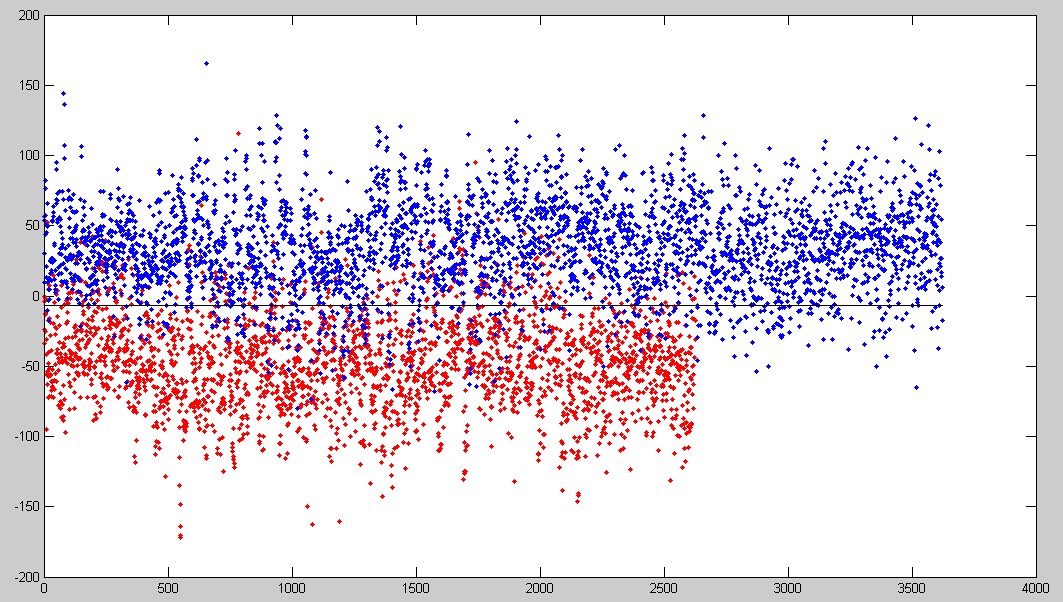
如上图所示,横坐标代表每一个样本的编号,这里没办法,我的男女样本数据库不一样大。。。不管了,然后纵坐标就是最后算出来的那个1维的数代表的那个样本,虽然有误差,但是基本大致上将男女分开来了。
不过呢,这种方法是性别识别里面最最最最最最最最最最最最最最最最最最简单的方法了,所以识别率大约85%~90%左右(当让也取决于你的训练库够不够强大),要在上去,不好意思,你要研究更加复杂的方法。
下面老规矩,贴出训练的代码和识别用的代码。
Code:
function train()
clc;
tic
M = 32;
N = 32;
if(exist('female_sample.mat','file')==2 && ...
exist('male_sample.mat','file')==2 && ...
exist('X.mat','file')==2 && ...
exist('target.mat','file')==2)
load female_sample.mat;
load male_sample.mat;
load X.mat;
load target.mat;
else
main_path = '.\train file\';
file = dir([main_path 'female']);
file = file(3:end);
female_sample = zeros(M*N,length(file));
for i = 1 : length(file)-1
img = imread([main_path 'female' '\' file(i).name]);
if(size(img,3) ~= 1)
img = rgb2gray(img);
end
img = imresize(img,[M,N]);
img = double(img);
img = reshape(img,M*N,1);
female_sample(:,i) = img;
end
female_sample_number = length(file);
file = dir([main_path 'male']);
file = file(3:end);
male_sample = zeros(M*N,length(file));
for i = 1 : length(file)-1
img = imread([main_path 'male' '\' file(i).name]);
if(size(img,3) ~= 1)
img = rgb2gray(img);
end
img = imresize(img,[M,N]);
img = double(img);
img = reshape(img,M*N,1);
male_sample(:,i) = img;
end
male_sample_number = length(file);
train_sample_avg = sum(female_sample,2) + sum(male_sample,2);
train_sample_avg = train_sample_avg / (female_sample_number + male_sample_number);
female_sample_extrac_avg = female_sample - repmat(train_sample_avg,1,female_sample_number);
male_sample_extrac_avg = male_sample - repmat(train_sample_avg,1,male_sample_number);
X = [female_sample_extrac_avg , male_sample_extrac_avg];
target = [ones(1,female_sample_number) , -1*ones(1,male_sample_number)];
save female_sample.mat female_sample;
save male_sample.mat male_sample;
save X.mat X;
save target.mat target;
end
Q = X*X';
[eig_vector eig_value] = eig(Q);
eig_value = abs(diag(eig_value)');
eig_thre = 0.989;
eig_value_re = fliplr(eig_value);
eig_value_re_cum = cumsum(eig_value_re)/sum(eig_value_re);
L = find(eig_value_re_cum >= eig_thre);
L = L(1);
eig_vector = fliplr(eig_vector);
W1 = eig_vector(:,1:L);
female_avg = sum(female_sample,2)/size(female_sample,2);
male_avg = sum(male_sample,2)/size(male_sample,2);
Xw = [female_sample-repmat(female_avg,1,size(female_sample,2)) ...
male_sample-repmat(male_avg,1,size(male_sample,2))];
Sw = (W1' * Xw) * Xw' * W1;
avg = sum([female_sample male_sample],2)/size(X,2);
Xb = [repmat(female_avg-avg,1,size(female_sample,2)) repmat(male_avg-avg,1,size(male_sample,2))];
Sb = (W1' * Xb) * Xb' * W1;
Q2 = inv(Sw)*Sb;
[eig_vector eig_value] = eig(Q2);
eig_value = abs(diag(eig_value)');
eig_thre = 0.99;
eig_value_re = eig_value;
eig_value_re_cum = cumsum(eig_value_re)/sum(eig_value_re);
p = find(eig_value_re_cum >= eig_thre);
p = p(1);
W2 = eig_vector(:,1:p);
Ws = W1*W2;
female_number = size(female_sample,2);
male_number = size(male_sample,2);
female_result = Ws'*X(:,1:female_number);
male_result = Ws'*X(:,female_number+1:(female_number+male_number));
plot(female_result,'r.');
hold on;
plot(male_result,'b.');
plot(1:max([female_number male_number]),mean(female_result)/2+mean(male_result)/2,'k','linewidth',4)
recognize_result = [female_result male_result];
train_sample_avg = sum(female_sample,2) + sum(male_sample,2);
train_sample_avg = train_sample_avg / (female_number + male_number);
save recognize_result.mat recognize_result;
save train_sample_avg.mat train_sample_avg;
save Ws.mat Ws;
save M.mat M;
save N.mat N;
save W1.mat W1;
toc
function indicator = genderrecognition(img)
load Ws.mat;
load train_sample_avg.mat;
load M.mat;
load N.mat;
load target.mat;
load recognize_result.mat;
if(size(img,3) ~= 1)
result = Ws'*(reshape(double(imresize(rgb2gray(img),[M,N])),M*N,1)-train_sample_avg);
else
result = Ws'*(reshape(double(imresize(img,[M,N])),M*N,1)-train_sample_avg);
end
[kk idx] = sort(abs(recognize_result - result));
%最近法
% indicator = target(idx(length(idx)));
%最远法
% indicator = -target(idx(1));
%KNN
k=31;
indicator = mode(-target(idx(1:k)));
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com
