某全国大型连锁酒店数据简析。。。
前阵子实验室某师弟(@小毛驴)从互联网上下载到了某名为RJ的全国大型连锁酒店的2KW条开房数据,在其强(bèi)烈(wǒ)要(suǒ)求(qǔ)下,我勉(xìng)为(gāo)其(cǎi)难(liè)地拿了这份数据。。。然后随(rèn)随(rèn)便(zhēn)便(zhēn)地剖析了一下。。。
其实因为数据量巨大,我很想用mathematica来直接分析,但是后来发现,一个文件300+M的大小,200W条数据,mathematica一读进来,不对,都还没读进来,就直接memory out了,然后机智的我想到先把数据分解,或者直接提取出我想要的那些条目,比如身份证号码啊,姓名啊,性别啊,地址啊,开房的年月日时分秒之类的,把这些保存成一个文件,显然这个文件没有那些乱七八糟的信息就会小很多。。。
但是——————首先你要有个可以读进来这些数据进行分解提取的方法。。。
显然的,这时候就是神器python的登场了,会python的同学就知道,python里面的读取文件用生成器简直无敌,你不需要将整个文件读进内存,处理到哪行就读取到哪行,保证内存使用一直恒定。。。读进每一行后,利用正则表达式提取出我想要的信息。。。我做了两个正则表达式,一个是提取性别-出生年月-开房时间,另一个是提取姓名,然后,每个300+M的文件,就变成大概50M左右和15M左右的一个文件了。。简直愉悦~【说起来,那些开房条目数据损坏(python文字无法解码)让我程序崩了很多次的那几位少年,茫茫人海中我们可以以这样的方式相联系,还真是缘分啊。。】
Python Code
然后呢,分解完就分析一下咯,首先是全国的开房人的姓名的研究,好吧,其实开房这两个字根本没用,我只是好不容易拿到一份这么多国人姓名的数据,想了解一下一些分布信息而已。。mathematica走起~
【其实最后我还是很囧,因为上面分割完的姓名的文件,mathematica最后还是最多一次读到600W条而已,再读200W条的话就还是memory out了,所以我研究姓名也是按600W条来分的,不是完整的2KW条,好吧,我一开始就不该选择用mathematica。。。】
首先是全国的姓氏的比例,TOP250如下:【以下图片如果觉得不清晰,点击可以查看清晰的。。。】

然后是姓名排行。。。唉,王伟同学,恭喜你头奖了!!咦?这么多人?不好意思,奖金你们只能评分了~
 三个字的TOP排在最后————王晓东。。。。
三个字的TOP排在最后————王晓东。。。。
然后我分析的一下单独的名的分布,首先找出两个字的名字的少男少女们,然后统计名字什么字眼用得最多:

终于知道为什么那么多人都叫”伟哥”了。。。
然后是三个字的名字的分布。。。叫建华建军建国的真是多到无法直视。。
 刚刚不是说到之前那种数据处理方法,mathematica一次只能处理600W条数据,所以我就想先通过别的软件先统计好一些数据,然后导入到mathematica中直接作图。。
刚刚不是说到之前那种数据处理方法,mathematica一次只能处理600W条数据,所以我就想先通过别的软件先统计好一些数据,然后导入到mathematica中直接作图。。
自然想到的就是python的字典,通过这个,就可以很方便的统计出同年出生同性别的人在同年同月同日开了房的数据,有了这个数据后,不关我是要统计基于出生年份,还是性别,还是开房时间的相关数据,我都可以很方便的累加特定的条目来得到结果!
下面是个简单的代码,这样一来,2KW条的数据瞬间就变成了一个很小很小的文件了,里面只有170000条数据,文件3.56M而已,这种数据mathematica一瞬间就能处理完的!!
Python Code
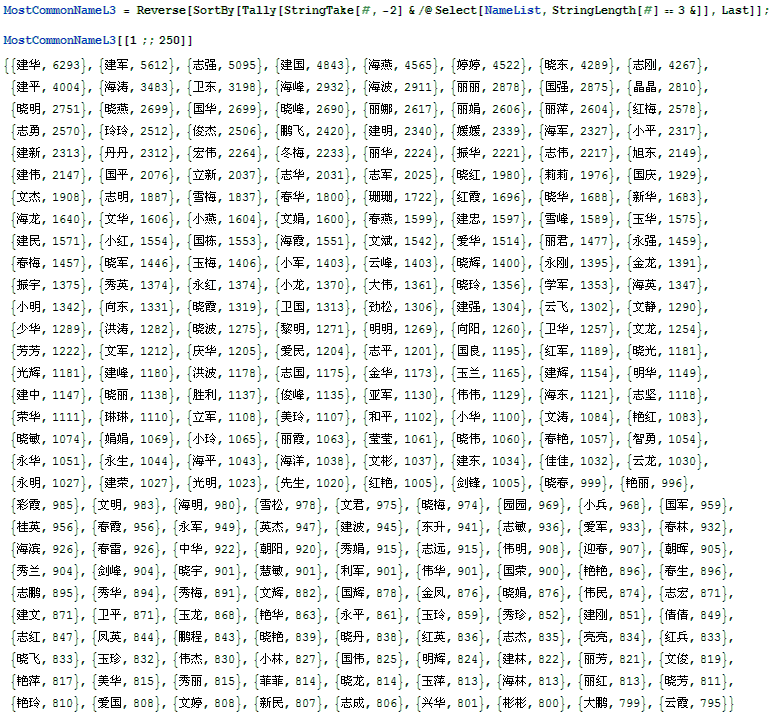
然后下面就是结果啦,首先算的就是不同年龄的人的开房的频数,结果如下:【再次提醒,点击可以看大图。。】
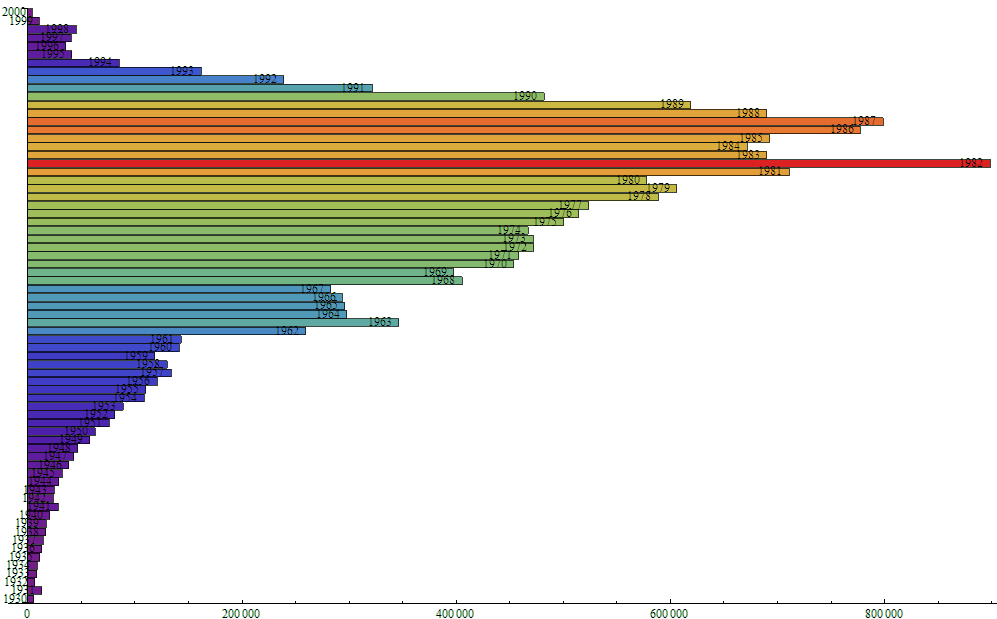 第一名是1982年的;
第一名是1982年的;
但是让人觉得别扭的是,这个形状居然不是一个平滑的”类钟”形,因为1982年那个高高的一条红的让人总觉得有猫腻,所以我后来根据身份证提取的出生年份的信息提取了一下出身年份的信息,统计了一下这个的出生年份的比例,结果————居然————是: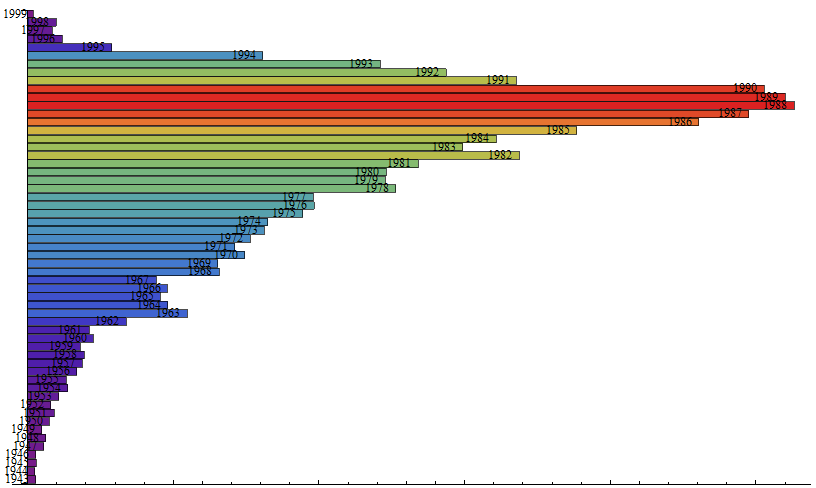 结论就是:虽然我不知道这家大型酒店的数据是怎么回事,开房时要怎么提供信息,但是在现实和最后的结果之间绝对有猫腻!!我查看了一下拿到的数据的文件,确实很多人身份证信息写的不是1982年,但是在出生年份那一栏那里确实是写的1982,所以,这是为啥呢?装熟??
结论就是:虽然我不知道这家大型酒店的数据是怎么回事,开房时要怎么提供信息,但是在现实和最后的结果之间绝对有猫腻!!我查看了一下拿到的数据的文件,确实很多人身份证信息写的不是1982年,但是在出生年份那一栏那里确实是写的1982,所以,这是为啥呢?装熟??
然后就分析了一下男女开房的比例,结果如下,不用多说,多的那个显然是男的。。。
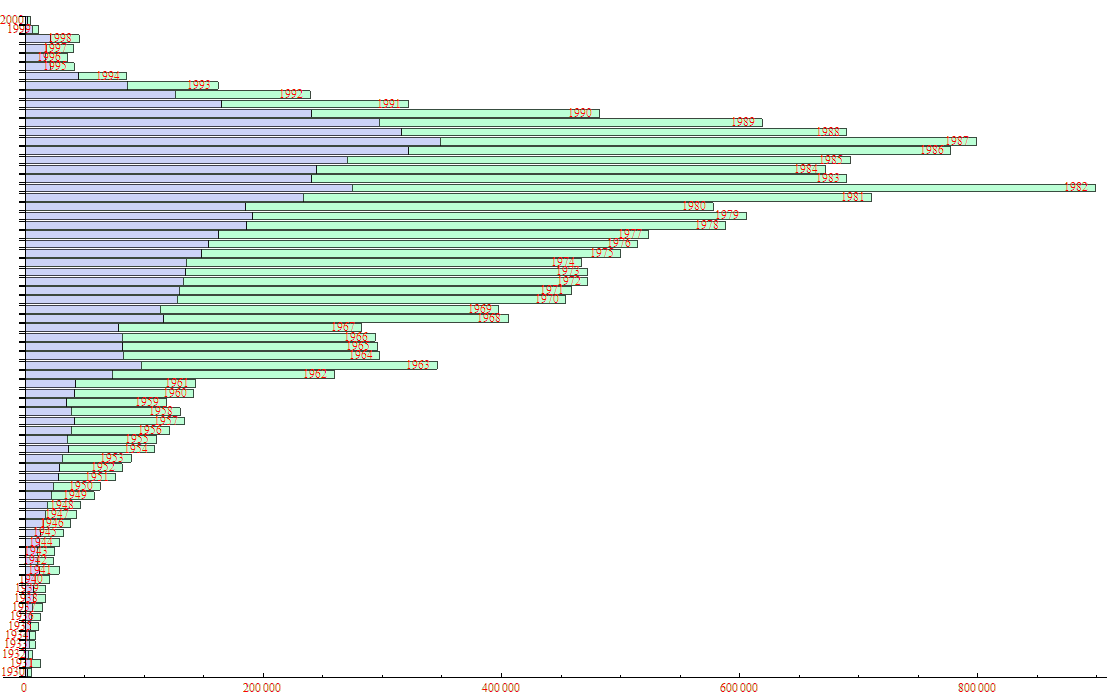 然后看看那家酒店的开房记录随着时间的变化关系是怎么样的,整个数据算出来跨度907天,约两年半,其中收尾两部分的数据可能不全,所以显然不正常,但是根据中间那部分看来,这家酒店应该是越开越大了,要不就是。。。开房的人真的越来越多了。。。显然,两个都是理由。。
然后看看那家酒店的开房记录随着时间的变化关系是怎么样的,整个数据算出来跨度907天,约两年半,其中收尾两部分的数据可能不全,所以显然不正常,但是根据中间那部分看来,这家酒店应该是越开越大了,要不就是。。。开房的人真的越来越多了。。。显然,两个都是理由。。
 虽然中间好像莫名其妙的丢失了好些天的数据,这不关我事,但是我比较好奇的是,传说中是不是情人节,光棍节,圣诞节这些时候开房数据会骤增,但是实际结果是,其实这些时候完全没什么变化。。。
虽然中间好像莫名其妙的丢失了好些天的数据,这不关我事,但是我比较好奇的是,传说中是不是情人节,光棍节,圣诞节这些时候开房数据会骤增,但是实际结果是,其实这些时候完全没什么变化。。。
那什么时候会有巨大变化呢?请看上图的箭头,我看了一下,都是五一和国庆,真是可怕。。。。
然后继续看一下开房的频数跟工作日的关系,结果如下。。。
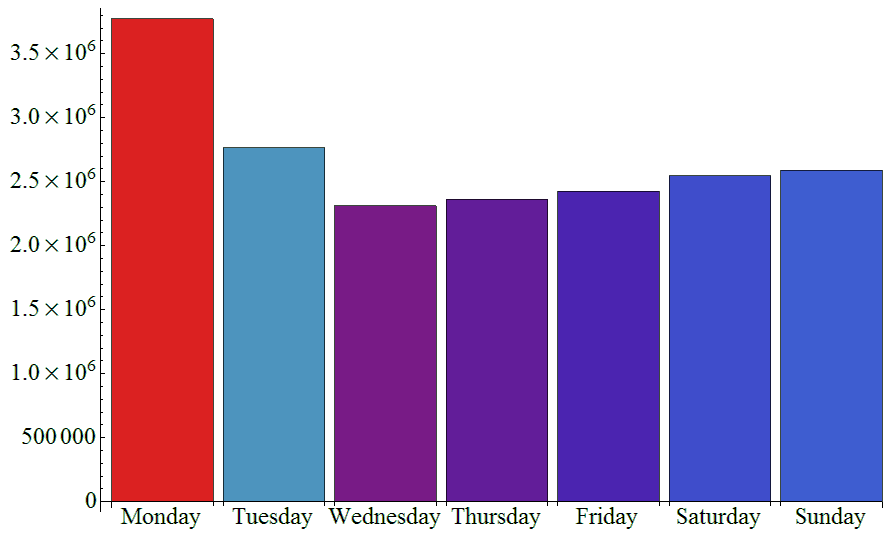 周一为什么会比较多呢?感觉没想到比较好的解释。。。谁能告诉我?
周一为什么会比较多呢?感觉没想到比较好的解释。。。谁能告诉我?
好了,这些是可以公开的分析结果,再往下,那就是禁止事项了。。。再次声明!本文纯属娱乐,一切责任,请不要找我。。。我什么都不知道,只是出来卖萌的而已。。
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com
(所以我写这个转载版权声明是在作死么?生怕别人查水表找不到我??!)

python真的是文本处理的神器啊
嗯,确实,它集成了Matlab,C++,Mathematica的种种优点。。虽然比较慢。。
膜拜中
其实这个没啥好膜拜的,数据别人拷给我的,处理又是没啥难度的活。。。
关于Mathematica的内存,是可以自由设定的。菜单:Edit> preferences> Evaluation
另外,Mathematica也支持部分导入。比如:Import[“F:/data/11.txt”, {“Data”, Range[3, 6]}]将导入文件中的3到6行数据
哦?这个下次有机会试试~
嗯。所以用M来处理大数据也是没问题的。另外,它还可以连接数据库。参见Help中的:DatabaseLink SQL Operations
Mma官方是说9.0增加了很多对大数据的支持,wolfram博客上面也有很多例子;但是手头没什么大数据可以玩。。。