互质数倒数乘积之和の研究【算法优化向】
![]() 上周开始一直在Euler Project上面刷题,玩得不亦乐乎,那种面对千奇百怪的问题,可以用自己手边的各种工具来“玩弄”的感觉真是让人欲罢不能,其实手头上也就4套工具,C++,Python,Matlab,Mathematica,主要用得最多的也就Mathematica,Python。
上周开始一直在Euler Project上面刷题,玩得不亦乐乎,那种面对千奇百怪的问题,可以用自己手边的各种工具来“玩弄”的感觉真是让人欲罢不能,其实手头上也就4套工具,C++,Python,Matlab,Mathematica,主要用得最多的也就Mathematica,Python。
好吧,讲正事,上周遇到一道题,可算把我两天给送进去了。。。。
题目链接可以参见这里,翻译过来是这样的:
1.1≤p<q≤M
2.p+q≥M
3.p和q互质
然后我们定义S(N)表示R(i)的和,2≤i<N
求:S(107)精确到小数点后4位
我开始用python试测了一下这个暴算的复杂度,直接跪了,所以我马上转战C++。。
首先我们可以根据题目表面要求写出第一套可以预知不可能成功的程序:
//辗转相除判断互质
inline bool IsCoprim(int m,int n)
{
int t;
while(n)
{
t = m%n;
m = n;
n = t;
}
return m == 1;
}
double R0(int M)
{
double sum = 0;
for(int p = 1;p < M;p++)
{
for(int q = p+1;q <= M;q++)
{
if(p+q >= M && IsCoprim(p,q))
sum += 1/double(p*q);
}
}
return sum;
}
double S0(int N)
{
double sum = 0;
for(int i = 2;i <= N;i++)
{
sum += R0(i);
}
return sum;
}
这个程序的结果我可以直接告诉你,在我的机子上,计算S(1000)花了6.2秒(下面所述时间全是Release版本的),S(1200)花了10.8秒,S(1500)花了21秒,后面我就直接不跑了,可以预见,越往后面需要的时间越长,S(5000)直接废了。。
然后想到了思路二,因为发现算R(M)的时候,其实做了很多无用的功,主要是因为很多需要的中间值都在算R(M-1)的时候算过了,就比如算R(10)的时候算过p=5,q=7的情况,而算R(11)的时候又算了一遍(不仅又算一遍,而且又一次辗转相处判断pq是否互质),所以我们可以用增量的方法来通过R(M-1)计算R(M)。
假设我们有了R(M-1)的结果,那么我们要怎么计算R(M)呢,两步:
第一步删去那些满足R(M-1)不满足R(M)的那些pq-Pairs,很容易看出来,就是要删去p+q==M-1的那些pq互质对
第二步要加上那些满足R(M)不满足R(M-1)的那些pq-Pairs,也很简单,就是q==M且pq互质的那些:
所以代码就变成:
//sum:R(M-1)的值
double R(int M,double sum)
{
for(int p = 1;p <= (M-2)/2;p++)
{
//减去p+q==M-1的互质对
int q = M-1-p;
if(IsCoprim(p,q))
sum -= 1/(double(p)*double(q));
}
for(int p = 1;p <= M-1;p++)
{
//加上q==M的互质对
if(IsCoprim(p,M))
sum += 1/(double(p)*double(M));
}
return sum;
}
其中在算第二步的时候,因为每次都要除以代码中的M,觉得很耗时间,所以可以先不算这个除法,最后一次算完,得到再一步提高的计算效率,如下:
//sum:R(M-1)的值
double R(int M,double sum)
{
for(int p = 1;p <= (M-2)/2;p++)
{
//减去p+q==M-1的互质对
int q = M-1-p;
if(IsCoprim(p,q))
sum -= 1/(double(p)*double(q));
}
double sum_temp = 0;
for(int p = 1;p <= M-1;p++)
{
//加上q==M的互质对
if(IsCoprim(p,M))
sum_temp += 1/double(p);
}
sum_temp /= double(M);
return sum += sum_temp;
}
现在这个算法速度大大提高,计算S(1000)只要47毫秒,计算S(1500)只要100毫秒,但是S(10000)要6.4秒,S(20000)要27.2秒,所以还是不够,远远不够。
算法还是可以继续改进的,因为题目最后要求的是S(N),上一步我们优化的是R,那么我就在想,可不可以直接跳过计算R,直接算S呢?也就是从S(M-1)直接到S(M)。
可以看到上面我们在计算R的时候是又加又减的,但是计算S的时候,根据定义,是R(i)的累加,那么会不会加减全部消掉了呢?或者抵消掉一部分呢?所以,以此为出发点,可以得到下一条改进:
是这样的,假设我们一开始有初始值R(2)=1/2,然后我们定义上一算法中,每次计算被减去的部分总和是D(n),被加上的总和是A(n),清楚一点说明的话就是:
R(2)=R(2)
R(3)=R(2)-D(3)+A(3)
R(4) =R(3)-D(4)+A(4)=R(2)-D(3)+A(3)-D(4)+A(4)
R(5) =R(4)-D(5)+A(5)=R(2)-D(3)+A(3)-D(4)+A(4)-D(5)+A(5)
……
R(M)=R(M-1)-D(M)+A(M)=R(2)-D(3)+A(3)-D(4)+A(4)-D(5)+A(5)-……-D(M)+A(M)
其中通过上一算法可知:
\(D(i)=\sum\dfrac{1}{pq}\),对所有p+q=i-1且互质的p,q
\(A(i)=\sum\dfrac{1}{pi}\),对所有互质的p,i
然后我们把上面那么多项最右边相加:
S(M)
=R(2)+R(3)+……+R(M)
=(M-1)× R(2)–(M-2)× D(3)+(M-3)× A(3)–(M-3)× D(4)+(M-3)×A(4)……-(M-i+1)× D(i)+(M-i+1)× A(i)…… -1×D(M)+1×A(M)
然后我们再举个例子看看互质对pq:
假设p=5,q=7,那么我们知道这个互质对会出现在D(13)中(因为5+7=13-1),也会出现在A(7)中,因为较大值是7;
再假设我们正在计算S(100),那么S(100)中可以知道D(13)被减去了100-13+1=88次,A(7)被加上了100-7+1=94次,所以我们可以知道在计算S(100)这个过程中,p=5,q=7这个互质对实际上出现了94-88=6次,也就是说可以直接加上6/(5×7);
更一般的说法,对于互质对p,q,他们会出现在 D(p+q+1)中,其中这个被减去了M-(p+q+1)+1=M-p-q次,也会出现在A(q)中,这个被加上了M-q+1次,所以最后出现次数是:p+1次;
但是,注意!对于p+q>M的互质对,如果上面计算成立,那么则是被减去了M-p-q<0次,出现负数是绝对不可能的,所以对于p+q≥M的互质对,就只有出现在A(q)中而不出现在D(p+q+1)中,所以出现次数是M-q+1次;
另外,我们可以把R(2)看成R(1)-D(2)+A(2),其中R(1)=0,所以就会变成下面这个直接计算S(M)的程序,其实就是对于所有1≤p<q≤M的所有的互质对p,q ,计算Weigth/(p·q),其中当p+q小于M的时候,Weigth=p+1,否则Weigth=M-q+1,就是这样而已。【你相信我们原本那道题可以变成这个样子么?————你当然应该相信!!】
double S(int M)
{
double sum = 0;
for(int q = 2;q <= M;q++)
{
double sum_t = 0;
for (int p = 1;p < q;p++)
{
if(IsCoprim(q,p))
sum_t += q+p<M ? (p+1)/double(p) : (M-q+1)/double(p);
}
sum += sum_t/double(q);
}
return sum;
}
代码超级简短,我非常喜欢这个化简!!!这个算法计算S(10000)需要4秒,S(20000)需要17秒。【我可是很享受这个慢慢提高速度的思考过程的!!】
接下来我们继续改进,我们可以测试一下上面代码大部分时间都在干嘛,其实不用测试也知道,就是辗转相除判断互质上面,这里可是花了大量的时间的,所以有什么办法可以不用这个方法判断互质呢?答案是,有的,但是这个基本是最简单的了。。。所以放弃这条思路!
但是我们换一条思路,我们上面说了,我们的方法变成了只要计算1≤p<q≤M的互质对p,q的乘积的倒数乘以一个权重而已,上面的代码的思路是扫描q从2到M,p从1到q-1,如果p,q互质,那么再计算权重。
但是,如果我们可以一开始知道哪些数是互质的,那不就可以省去判断互质这一步了么?
孔子曰:“有问题,找维基娘!!”庄子也曰过:“孔子说的对!!”
然后维基娘可以找到一个生成所有互质对的方法:
我们一开始把质数对(2,1)和(3,1)分别作为起始点(m,n),然后生成三个新的质数对(2m-n,m)(2m+n,m)(m+2n,n),维基娘她对天发誓了,这个方法不断迭代下去可以生成无遗漏的所有的互质对!!所以我们就相信她吧~
【其实维基娘页面上还是写错了,上面写的是:starting from (2,1) (for even-odd or odd-even pairs) or from (3,1)(for odd-odd pairs)…This scheme is exhaustive and non-redundant with no invalid members.如果真要生成所有的互质对的话,这个or必须改成and】
这个构造方法有一个很好的特性,(m,n)只要m>n,那么构造出来的(2m-n,m)(2m+n,n)(m+2n,n)还是满足左边的数大于右边的数,所以我们也可以很容易的写出互质对生成的停止条件,就是左边的数(较大的数)大于M之后就不再生成了!
另外一个最重要的特点就是——绝对不会出现重复!!!这要是出现重复,我们就算法肯定就错了。。
所以我们可以构建一个队列,然后一步步展开成为所有的互质对,再也不用那个辗转相除了!!
//定义互质对
class CCorprimePair
{
public:
CCorprimePair(void);
~CCorprimePair(void);
CCorprimePair(int xx,int yy):x(xx),y(yy){}
int x;
int y;
};
double S4(int M)
{
double sum = 0;
list<CCorprimePair> CoprimePairList;
int m,n;
//初始互质对先进入队列
CoprimePairList.push_back(CCorprimePair(2,1));
CoprimePairList.push_back(CCorprimePair(3,1));
while(!CoprimePairList.empty())//只要队列非空
{
CCorprimePair temp = CoprimePairList.front();
//还是上面那个算法
if(temp.x+temp.y >= M)
sum += (M-temp.x+1)/double(temp.x*temp.y);
else
sum += (temp.y+1)/double(temp.x*temp.y);
CoprimePairList.pop_front();
//生成下一个互质对
m = 2*temp.x-temp.y;
n = temp.x;
if(m <= M)
CoprimePairList.push_back(CCorprimePair(m,n));
m = 2*temp.x+temp.y;
n = temp.x;
if(m <= M)
CoprimePairList.push_back(CCorprimePair(m,n));
m = temp.x+2*temp.y;
n = temp.y;
if(m <= M)
CoprimePairList.push_back(CCorprimePair(m,n));
}
return sum;
}
稍微看一下代码,有C++经验的人就会知道,其实上面的代码超级慢,算S(5000)就要15秒了,其实这个不是算法的错,是因为上面用的是链表,动态生成了很多互质对,申请了很多内存空间,众所周知C++对new函数的操作是非常慢的,这也是为什么高速服务器绝对不能用malloc和new这些函数!
那怎么办呢?自己写一个循环队列呗,队列长度一开始固定好,那么就不用像链表一样动态生成节点浪费时间了。【话说STL里面是不是没有循环队列这个数据结构?】
#define MAX_QUEUE_SIZE 99999999
CCorprimePair* CirQueue = new CCorprimePair[MAX_QUEUE_SIZE];
int p_head = 0;
int p_tail = 1;
//入队
void push(CCorprimePair t)
{
CirQueue[(MAX_QUEUE_SIZE+p_tail-1)%MAX_QUEUE_SIZE] = t;
p_tail = (p_tail+1)%MAX_QUEUE_SIZE;
}
//出队
CCorprimePair pop()
{
CCorprimePair result = CirQueue[p_head];
p_head = (p_head+1)%MAX_QUEUE_SIZE;
return result;
}
bool IsQueueEmpty()
{
return (p_tail-p_head==1) || (p_head == MAX_QUEUE_SIZE-1 && p_tail == 0);
}
double S4v2(int M)
{
double sum = 0;
int m,n;
push(CCorprimePair(2,1));
push(CCorprimePair(3,1));
while(!IsQueueEmpty())
{
CCorprimePair temp = pop();
if(temp.x+temp.y >= M)
sum += (M-temp.x+1)/double(temp.x*temp.y);
else
sum += (temp.y+1)/double(temp.x*temp.y);
m = 2*temp.x-temp.y;
n = temp.x;
if(m <= M)
push(CCorprimePair(m,n));
m = 2*temp.x+temp.y;
n = temp.x;
if(m <= M)
push(CCorprimePair(m,n));
m = temp.x+2*temp.y;
n = temp.y;
if(m <= M)
push(CCorprimePair(m,n));
}
return sum;
}
你猜这个速度多少?计算S(10000)只要0.9秒,S(20000)只要3.6秒!!S(30000)只要8秒!!
这个是不是在没有上升空间了呢?上面中有很多1/(p·q)的计算,我们可以实现把1/p,1/q预先计算出来,这样就变成查表计算乘法了,上面运用这个可以改进20%的时间左右!!
double S4v3(int M)
{
//预先求值
double* divide_result = new double[M];
for(int i = 1;i <= M;i++)
divide_result[i] = 1 / double(i);
double sum = 0;
int m,n;
push(CCorprimePair(2,1));
push(CCorprimePair(3,1));
while(!IsQueueEmpty())
{
CCorprimePair temp = pop();
if(temp.x+temp.y >= M)
sum += (M-temp.x+1)*divide_result[temp.x]*divide_result[temp.y];
else
sum += (temp.y+1)*divide_result[temp.x]*divide_result[temp.y];
m = 2*temp.x-temp.y;
n = temp.x;
if(m <= M)
push(CCorprimePair(m,n));
m = 2*temp.x+temp.y;
n = temp.x;
if(m <= M)
push(CCorprimePair(m,n));
m = temp.x+2*temp.y;
n = temp.y;
if(m <= M)
push(CCorprimePair(m,n));
}
return sum;
}
其实上面的方法也有一个本质的缺点:循环链表的大小限制了计算的规模,在C++里面生成的数字大小有上限,所以计算S(107)基本是不可能的!!
我试验过的还有一个改进方法:
我们上面的计算过程中一直在计算Weigth/p/q【虽然后来变成先算好1/p和1/q的值,变成乘法以节省时间了。】,但是设想,假设我们知道和q互质的所有的数p(显然应该有p<q),那么我们就可以先计算Weigth/p的和,最后再一口气乘以1/q,这样可以节省很多乘除的时间,
也可以反过来想,我们对于固定的p,计算出所有的大于p且与p互质的q,然后计算Weigth/q的和,最后再一口气乘以1/p。
但是要怎么做到呢?因为我发现比较坑爹的就是上面那个质数对的生成方法出来的结果是毫无规律的,好吧,其实应该说,规律不好掌握。
下图来自维基娘,同样的点代表的互质对是同一层迭代生成的结果。
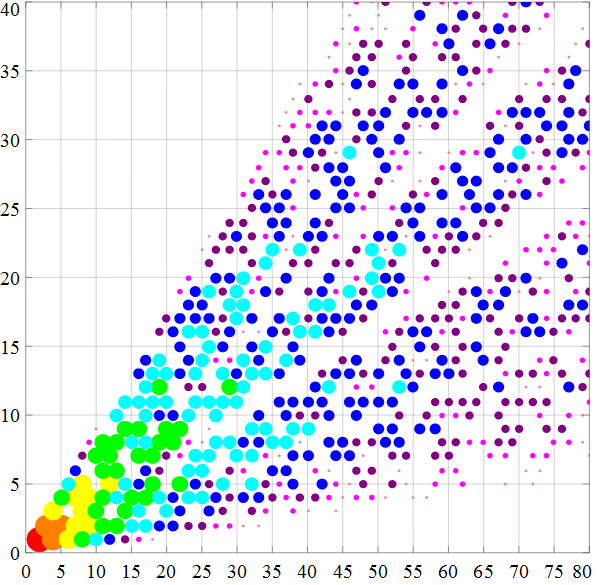
虽然这个方法表面不好找规律,但是我们可以构造规律!!
观察互质对的生成方法,(m,n)->(2m-n,m)(2m+n,m)(m+2n,n),其中m>n;
假设我们要生成与2互质的所有数,要怎么生成呢?我们现有(2,1),然后我们代入前两个(2m-n,m)(2m+n,m),就得到(3,2)(5,2)了,然后对于(3,2),我们不断迭代调用(m,n)->(m+2n,n),就得到(7,2)(11,2)(15,2)…对于(5,2)不断迭代调用(m,n)->(m+2n,n),就得到(9,2)(13,2)(17,2)…这样我们就生成了所有与2互质的且比2大的所有的数了。
然后我们要计算3的时候要怎么做,首先我们要找出比3小且与其互质的数,根据计算2的时候,我们知道(3,2)这个互质对,另外必然还有(3,1),我们对这两个互质对分别调用(m,n)->(2m-n,m)(2m+n,m)就得到:(4,3)(8,3)(5,3)(7,3),然后我们对这四组分别不断迭代调用(m,n)->(m+2n,n),就可以得到比3大的所有互质的数了。
更一般的说法,假设要计算所有比k大的所有的互质的数,那么先要找到比k小且与k互质的数y1,y2,y3…yb,这个可以通过计算2~k-1的时候就已经存下来了,然后对于这些互质对(k,y1)(k,y2)(k,y3)….(k,yb)分别调用(m,n)->(2m-n,m)(2m+n,m),就可以得到2b个互质对,然后对这2b个互质对分别不断调用(m,n)->(2m-n,m)(2m+n,m)就可以生成全部大于k且与k互质的数了!!
这个思路有点繁琐,而且写起来也很麻烦,所以下面的代码请无视吧~我也懒得注释了。。
double S5(int M)
{
double* divide_result = new double[M];
for(int i = 1;i <= M;i++)
{
divide_result[i] = 1 / double(i);
}
double sum = 0;
int** SeedList = new int*[M-1];//存2-M
int* idx = new int[M-1];
for(int i = 0;i < M-1;i++)
{
idx[i] = 1;
SeedList[i] = new int[i+1];
SeedList[i][0] = 1;
}
//处理j==1
for(int i = 2;i <= M-2;i++)
{
sum += divide_result[i];
}
sum *= 2;
for(int i = M-1;i <= M;i++)
{
if(i>1)
sum += (M-i+1)*divide_result[i];
}
//2以上
int m;
int pair_t;
for(int j = 2;j <= M-1 ;j++)
{
double sum_t = 0;
for(int seedc = 0;seedc < idx[j-2];seedc++)
{
pair_t = SeedList[j-2][seedc];
m = 2*j-pair_t;
while(m <= M)
{
SeedList[m-2][idx[m-2]++] = j;
if(m+j < M)
sum_t += (j+1)*divide_result[m];
else
sum_t += (M-m+1)*divide_result[m];
m = m + 2*j;
}
m = 2*j+pair_t;
while(m <= M)
{
SeedList[m-2][idx[m-2]++] = j;
if(m+j < M)
sum_t += (j+1)*divide_result[m];
else
sum_t += (M-m+1)*divide_result[m];
m = m + 2*j;
}
}
sum += sum_t*divide_result[j];
}
return sum;
}
这个算法其实改进不是很大,S(10000)要0.7秒,但是越往大走,优化效果越看不到。。。所以我并不是很喜欢这个算法,编程意义上不喜欢,虽然数学意义上还是觉得挺好的~
走到这一步,我基本发现了,我他喵的完全走错路了!!!我已经常数时间内计算出所有的互质对,以及他们的Weigth了,但是对于107这个数量级,互质对实在太多了!!
下面是一个我觉得很有前途的编程意义上的算法,虽然还是有着完全无法解决的一个巨大缺点!!
回到我们前面算R的那里,我们抛开互质对的生成,抛开直接算S的思路,在思考一下算R的过程,思路出发点是下面这个大家都很熟悉的公式:
$$\dfrac{1}{p\times q}=\dfrac{1}{q-p}(\dfrac{1}{p}-\dfrac{1}{q})$$
而且有这个的话,我们很快就可以联想到下面这个快速计算的公式:
$$\dfrac{1}{p(p+k)}+\dfrac{1}{(p+k)(p+2k)}+\dfrac{1}{(p+2k)(p+3k)}+…+\dfrac{1}{(p+(m-1)k)(p+mk)}=\dfrac{1}{k}(\dfrac{1}{p}-\dfrac{1}{p+mk})$$
有一个不言而喻的结论(虽然高中时代我也很讨厌别人这么说。。):假设p和p+k互质,那么p+k与p+2k,p+2k与p+3k,p+(m-1)k与p+mk必然互质!!
所以算法很容易想到这个算R(M)的算法:
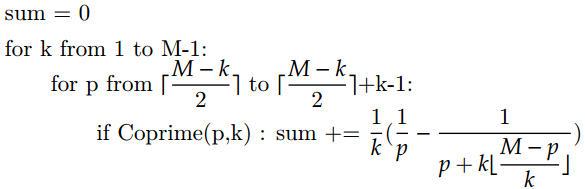 这个算法可以大规模减少计算互质的次数,这样就减少计算1/(p·q)的次数,这个好处是啥?我们知道这个题目中可能要计算几千百亿个除法,然后相加,这样最后机器的计算精度就会对最终结果造成影响了!大量减少计算次数就可以减少这个问题带来的危害!!这就是我为什么觉得这条思路比较有潜力的原因。。
这个算法可以大规模减少计算互质的次数,这样就减少计算1/(p·q)的次数,这个好处是啥?我们知道这个题目中可能要计算几千百亿个除法,然后相加,这样最后机器的计算精度就会对最终结果造成影响了!大量减少计算次数就可以减少这个问题带来的危害!!这就是我为什么觉得这条思路比较有潜力的原因。。
但是,回到很早之前那个问题:还是要判断互质,唉。。。然后我也没想到什么好的改进的方法。。
代码如下:
double R6(int M)
{
double sum = 0;
for(int step = 1;step <= M-1;step++)
{
for(int i = ceil((double(M)-step)/2);i <= ceil((double(M)-step)/2)+step-1;i++)
{
if(IsCoprim(i,step))
{
sum += 1/double(step)*(1/double(i)-1/double(i+int((M-i)/step)*step));
}
}
}
return sum;
}
double S6(int N)
{
double sum = 0;
for(int i = 2;i <= N;i++)
{
sum += R6(i);
}
return sum;
}
所以最后的结论,我预计,如果要在允许时间内解决这个问题,数论的一些知识必然必不可少,直觉上告诉我,这道题的解法应该用上了欧拉函数。。。
不知道完整地看到这里的少年你对这道题有啥见解??
【暂时。。完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

到后面就难以理解你的算法优化了,我刚学数论函数,很多函数怎么用尽编程还不懂……感觉你好厉害!
其实我这个算到最后,问题本身还是没解决。。还是太慢。。数论完全不懂啊。。
虽然没有解决,但是你已经做了很大的优化。好厉害!好佩服你!