Ababoost
毕设时曾经有个模式识别的东西想用Adaboost算法来实现,然后自己就傻不溜秋的用matlab写了一个API,也是为了方便将来用,后来不但没用上这个算法,而且指导老师跟我说,你难道不知道有个软件叫weka么??让后我就SB了。。。
不管怎么样,好歹是学过且用过的。
Adaboost的算法思想就是把许许多多的弱分类器合并起来,变成一个强分类器。
在二分类问题中,所谓弱分类器就是对于训练集里面,识别率略高于50%的分类器,其实就是比随机乱猜好一点的分类器,即便是51%的识别率我们也能称之为弱分类器。
好吧,为了科普一点。。所谓的分类器,就是由一个特征,一个方向,一个阈值组成的,比如说判断一幅图像是黑夜还是白天,我们可以选择一个特征,那就是图像的灰度图的平均值,这个叫特征值,假设我们把图像时白天成为1,黑夜成为-1,那么我们可以构建一个简单的分类器,就是灰度值大于125那么就是1,小于125就是-1,所以我们懂啦,大于还是小于那就是分类器的方向,125就是阈值。
一般模式识别里面的分类器都是这样的。只是一般对象的特征值不一定就是一个数,也可能是一个向量,或者一个矩阵。假设这个特征向量是[x1, x2, x3, x4…xn],然后分类器就是判断f(x1, x2, x3, x4…xn)>θ。
而adaboost的思想就是三个臭皮匠赛过诸葛亮,通过把弱分类器级联起来,这样就得到一个强分类器。不懂?请看下图:
 如果让你画一条线就把上图中红色和蓝色区别出来,那显然是不可能的,对不?
如果让你画一条线就把上图中红色和蓝色区别出来,那显然是不可能的,对不?
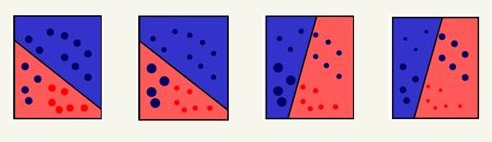 上面两种画法是 一把能想到的比较好的分类方法,虽然不是100%的分别率,但是还是超过50%的,然后呢,要怎么样才可以合成一个强分类器呢?
上面两种画法是 一把能想到的比较好的分类方法,虽然不是100%的分别率,但是还是超过50%的,然后呢,要怎么样才可以合成一个强分类器呢?
 就是这样,哈哈,别说我开玩笑啦,好吧,我这里不想写表达式,看我这么说你们懂不懂吧,就是说我们现在有两个弱分类器,第一个弱分类器划出一条线,说上篮下红,(见上上图的前两个),我们认为这个分类器是f1(x,y),它的阈值θ1 ,第二个弱分类器划出另一条线,说上篮下红(见上上图的后两个),我们认为这个分类器是f2(x,y),它的阈值θ2。
就是这样,哈哈,别说我开玩笑啦,好吧,我这里不想写表达式,看我这么说你们懂不懂吧,就是说我们现在有两个弱分类器,第一个弱分类器划出一条线,说上篮下红,(见上上图的前两个),我们认为这个分类器是f1(x,y),它的阈值θ1 ,第二个弱分类器划出另一条线,说上篮下红(见上上图的后两个),我们认为这个分类器是f2(x,y),它的阈值θ2。
然后现在有个点我想判断它属于红还是属于蓝,那我就分别用这个两个分类器判断一下,给个结果,假设如果分类器觉得是蓝那么它会输出1,否则它会输出-1。现在我们给两个分类器都赋予一个权值,假设是一个是0.4,一个是0.6,那么识别过程中,如果两个都认为是1,那么输出结果就是1,如果都认为是-1,那么结果显然也是-1,如果权重一个认为是1,一个认为是-1的话,那么就是要加权!
在上面那个例子中,假设我们认为第一个分类器的权重是0.6,第二个分类器的权重是0.4的话,那么上图中两条线把图分成4块,其中有三块是可以识别正确的,这样就比了两个弱分类器都要强,因为每个弱分类器都只能正确识别上图4块中的两块。
而我们的Adaboost算法就有两件事情要做,一是怎么样才可以寻找到好的弱分类器,二是怎么样分配权值才可以把强分类器的识别率提到最大!
我们的运算方法如下:
- 首先我们把每个训练样本都打上tag,也就是表明它是正样本还是负样本,为了表示特征值,我们用(x,y)来表示一个样本,其中x是特征值,加了粗表示不一定是一个数,也可能是一个向量,y=±1;
- 每个样本我们都设置一个权重,初始化为di = 1/N,其中N是总样本数。
- 在所有可能的分类器中我们需找一个最好的弱分类器hi,它在所有候选的分类器中具有最好的识别率。
- 计算这个弱分类器的误识别率ei,就是把所有错误识别的样本的权重相加。
- 然后我们就根据弱分类器的误识别率得到弱分类器的权重:
\(\alpha_i=\dfrac{1}{2}ln\dfrac{1-e_i}{e_i}\) - 接下来我们就要更新一下每个样本的权重,原则是这样的,就是如果分类器没有将其正确分类,那么我们认为这是一个重要的样本,后面机器学习过程中要重点对待,所以要提高他的权重,识别正确的话可以降低后面对它的重视程度,所以\(d’_i=d_ie^{-\alpha_iy_ih_i(x)}\),这个更新公式可以这么理解,如果hi分类分类正确的话,那么yihi(x)=1,否则等于-1,正确就降低样本权值,错误就提高权值,就是这样。
- 所有样本的权值归一化,就是让他们的和为1。
- 合成的强分类器就是\(\sum\alpha_ih_i(x)\),如果对于所有测试样本,这个强分类器的分别率还没有达到要求,那么就回到步骤3,寻找一个新的弱分类器级联进来。不达目的不罢休!!
function Adaboost()
% clc;
all_value = importdata('DTW_TWO_DIM_DIST_a_r_25.mat');%%训练数据
all_value = abs(all_value);
[m n] = size(all_value);
train_begin = [1 100];
test_begin = [101 110];
train_num = train_begin(2)-train_begin(1)+1;
test_num = test_begin(2)-test_begin(1)+1;
train_value = zeros(train_num*10,n);
test_value = zeros(test_num*10,n);
train_cc = 1;
test_cc = 1;
for i = 0:9
for j = 1 : 110
if(j< =train_begin(2) && j>=train_begin(1))
train_value(train_cc,:) = all_value(i*110+j,:);
train_cc = train_cc + 1;
end
if(j< =test_begin(2) && j>=test_begin(1))
test_value(test_cc,:) = all_value(i*110+j,:);
test_cc = test_cc + 1;
end
end
end
judge = zeros(10,test_num*10);
for Number = 0 : 9
target = zeros(1,train_num*10);
target(Number*train_num+1:(Number+1)*train_num) = 1;
target = target';
[Flag Threshold Polarity Alpha] = AdaboostTrain(train_value,target,50);
T = length(Flag);
w_ans=zeros(1,test_num*10);
newtarget=zeros(1,test_num*10);
for k=1:test_num*10
for i=1:T
idx=Flag(i);
value=test_value(k,idx);
if Polarity(i)*value< Polarity(i)*Threshold(i)
w_ans(k)=w_ans(k)+Alpha(i);
else
w_ans(k)=w_ans(k)-Alpha(i);
end
end
if w_ans(k)>0
newtarget(k)=1;
else
newtarget(k)=0;
end
end
judge(Number+1,:) = w_ans;
end
save adaboost_result.mat judge;
% % delta=xor(target',newtarget);
% % figure;
% % sum(delta)
% % subplot(211);plot(w_ans);
% % subplot(212);plot(delta);
w = importdata('adaboost_result.mat');
judge = zeros(10,10);
for i = 1 : test_num*10
temp = w(:,i);
result = find(temp == max(temp));
judge(floor((i-1)/test_num)+1,result) = judge(floor((i-1)/test_num)+1,result)+1;
end
judge
rate = zeros(1,10);
for i = 1 : 10
rate(i) = judge(i,i)/sum(judge(i,:));
end
rate
mean(rate)
%%target:1 正样本 0 负样本
function [Flag Threshold Polarity Alpha] = AdaboostTrain(trainset,target,Iter)
[allnum feacture_dimem] = size(trainset);
weigth = ones(1,allnum)/allnum;
% weigth = zeros(1,allnum);
% weigth(target==1) = 0.5/110;
% weigth(target==0) = 0.5/990;
Threshold = zeros(1,Iter);
Flag=zeros(1,Iter);
Polarity=zeros(1,Iter);
Error =zeros(1,Iter);
Beta=zeros(1,Iter);
actual_iter_num = 0;
for ii = 1 : Iter
ii
actual_iter_num = actual_iter_num+1;
error = 0.5;
for k = 1 : feacture_dimem
[bestThresh,bestParity,bestErr,ans_target] = weaklearner(trainset(:,k),weigth,target,allnum);
if bestErr< =error&&bestErr~=0
error=bestErr;
Error(ii)=bestErr;
Threshold(ii)=bestThresh;
Flag(ii)=k;
Polarity(ii)=bestParity;
Beta(ii)= bestErr / (1 - bestErr);%
new_target=ans_target;
end
end
delta = xor(target,new_target);%if h(xi)yi = -1 delta=1;
weigth = weigth .* (Beta(ii) .^ (1-delta'));
weigth = weigth./sum(weigth);
out=TestStrong(trainset,target,allnum,Threshold, Flag,Polarity,Beta,ii);
if(out == 1)
break;
end
end
Threshold = Threshold(1:actual_iter_num);
Flag = Flag(1:actual_iter_num);
Polarity = Polarity(1:actual_iter_num);
Beta = Beta(1:actual_iter_num);
Alpha = log(1./Beta)/2;
function [bestThresh,bestParity,bestErr,ans_target]
=weaklearner(data,weight,target,num)
% posWeight = sum(weigth(target==1));
% negWeight = sum(weigth(target==0));
posWeight=0;%正样本的权重之和
negWeight=0;
for i=1:num
if target(i)==1
posWeight=weight(i)+posWeight;
elseif target(i)==0
negWeight=weight(i)+negWeight;
end
end
[data_sort,Idx]=sort(data);
lposweight=0;
lnegweight=0;
bestErr=0.5;
bestParity=0;
bestThresh=-1;
for i = 2 : num
if target(Idx(i-1))==1
lposweight=weight(Idx(i-1))+lposweight;
else
lnegweight=weight(Idx(i-1))+lnegweight;
end
if ( lposweight+negWeight-lnegweight ) < bestErr
bestErr = lposweight + negWeight - lnegweight;
bestParity = -1; %分类器种类
bestThresh = (data_sort(i) + data_sort(i-1)) / 2;%阈值
elseif lnegweight+posWeight-lposweight < bestErr
bestErr = lnegweight + posWeight - lposweight;
bestParity = 1;
bestThresh = (data_sort(i) + data_sort(i-1)) / 2;
end
end
ans_target = (bestParity*data<bestParity*bestThresh);
function out=TestStrong(value_theta,target,num,Threshold, Flag,Polarity,Beta,T)
w_ans=zeros(1,num);
newtarget=zeros(1,num);
for k=1:num
for i=1:T
idx=Flag(i);
value=value_theta(k,idx);
if Polarity(i)*value< Polarity(i)*Threshold(i)
w_ans(k)=w_ans(k)+log(1/Beta(i))/2;
else
w_ans(k)=w_ans(k)-log(1/Beta(i))/2;
end
end
if w_ans(k)>0
newtarget(k)=1;
else
newtarget(k)=0;
end
end
delta=xor(target',newtarget);
out=0;
if sum(delta)< 1
out=1;
end
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

本科就做模式识别这么高大上的东西了。
本科做这个的很多吧。。
Boost classifiers 一共有四个:DAB – Discrete AdaBoost, RAB – Real AdaBoost, LB – LogitBoost, GAB – Gentle AdaBoost.
不知你用的是哪一种。
算了,这问题不重要。
其实有 C++ 机器学习框架 mlpack 实现了 adaboost, 反正我不喜欢 Java.