Project Euler个人解答(Problem 51~60)
![]() 好了,这一篇总算写完了。。。其实这一P里面就第一题和最后一题比较难,其他都没花什么时间。。
好了,这一篇总算写完了。。。其实这一P里面就第一题和最后一题比较难,其他都没花什么时间。。
总而言之,言而总之,最近先不更这个了,因为更一个这个好他喵的花时间啊。。所以@saya,你就先慢慢看前面的吧。。
接下来我要好好在寒假之前把论文给搞定,然后安心坐等毕业,走向人生巅峰!!想想还有点小激动?
Problem 51:Prime digit replacements
By replacing the 1st digit of the 2-digit number *3, it turns out that six of the nine possible values: 13, 23, 43, 53, 73, and 83, are all prime.
By replacing the 3rd and 4th digits of 56**3 with the same digit, this 5-digit number is the first example having seven primes among the ten generated numbers, yielding the family: 56003, 56113, 56333, 56443, 56663, 56773, and 56993. Consequently 56003, being the first member of this family, is the smallest prime with this property.Find the smallest prime which, by replacing part of the number (not necessarily adjacent digits) with the same digit, is part of an eight prime value family.
翻译:
通过置换*3的第一位得到的9个数中,有六个是质数:13,23,43,53,73和83。
通过用同样的数字置换56**3的第三位和第四位,这个五位数是第一个能够得到七个质数的数字,得到的质数是:56003, 56113, 56333, 56443, 56663, 56773, 和 56993。因此其中最小的56003就是具有这个性质的最小的质数。
找出最小的质数,通过用同样的数字置换其中的一部分(不一定是相邻的部分),能够得到八个质数。
这道题死算的话会非常消耗时间,但是思考一下,还是有较大的优化空间;
首先,对于需找质数,因为必然不可能是1位数,所以可以认为最后一位必然是1,3,7,9;
其次,由于我们要寻找的那个数是8个数里面最小的,所以被替换的部分必须是0或者1或者2,不然3,4,5,6,7,8,9最多只有七个质数;所以我们这样就可以大幅度减少需要判断的次数了;
再其次,我们可以预估一下需要被替换的位数是多少位,这个预筛选可以通过能否被3整除来获得,就好像对于题目中所说的56**3,我们可以认为需要被替换的位数是两位,除去这两位之外剩余位数之和是5+6+3=14,这个数被3整除余2,然后我们可以计算一下,对于已知剩余位数之和被3整除的余数,以及需要替换的位数,可以算出替换为0~9之后绝对不可能是质数的个数:
假设剩余位数之和被3除余k,然后需要替换的位数是n位,那么将被替换的n位换成n个0~9,这10个数分别被3除余数是:\(mod(k+i n,3)\),其中i=0,1,2,3…9;我们可以计算一下这张表:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 0 | 6 | 6 | 0 | 6 | 6 | 0 | 6 | 6 | 0 | 6 |
| 1 | 7 | 7 | 10 | 7 | 7 | 10 | 7 | 7 | 10 | 7 |
| 2 | 7 | 7 | 10 | 7 | 7 | 10 | 7 | 7 | 10 | 7 |
横向对应的是其余位数之和被3除的余数,纵向是需要替换的位数,可以看出,想要替换出8(或以上)个不被3整除的数的话,那么只有一种可能,替换的个数为3的倍数,而且其余位数之和不为0,比如我们看1*5****就绝对不可能满足题目条件,因为被替换的个数为5,再看1*4**也绝对不可能,因为除去替换位数外,剩余位数之和为1+4=5;
然后再结合上面判断的推论,质数最后一位必须是1,3,7,9,那么也说明了一件事,要被替换的位数绝对不可能在最后一位!!
所以我们的算法要找的数必须要满足以下条件:
- 最后一位必须是1,3,7,9其中之一
- 除去最后一位,剩余位数至少有3个0或者三个1或者三个2
- 这个数本身是个质数【顺便保证了这个数不可能被3整除】
在上面条件满足情况下,我们再生成替换的Mask,替换范围是除最后一位以外的剩余位数里面挑选3k位;
其实这样剩余要排除的情况就很少了,比如对于五位数,本身是质数,最后一位是1,3,7,9,除去最后一位还剩余3个0或者三个1或者三个2的就不多,再其次,替换模板本身就很少,对于五位数就只有(下面结果就是代码中的generate_Mask生成的):
[0, 1, 1, 1, 0],[1, 0, 1, 1, 0]
[1, 1, 0, 1, 0],[1, 1, 1, 0, 0]
其中1代表要被替换的位;
而对于六位数:
[0, 0, 1, 1, 1, 0],[0, 1, 0, 1, 1, 0]
[0, 1, 1, 0, 1, 0],[0, 1, 1, 1, 0, 0]
[1, 0, 0, 1, 1, 0],[1, 0, 1, 0, 1, 0]
[1, 0, 1, 1, 0, 0],[1, 1, 0, 0, 1, 0]
[1, 1, 0, 1, 0, 0],[1, 1, 1, 0, 0, 0]
下面python代码出结果只要1秒左右,代码有点长,但是也比较好懂;;
Code:Python
#判断是否是质数
def PrimeQ(n):
for i in range(2,int(sqrt(n))+1):
if n%i == 0:
return False;
return True;
#生成n挑k个数的模板,比如bits=5,k=3,返回会类似[1,0,1,0,1]
def NPickK(bits,k):
if k == 0:
yield [0]*bits
elif k == bits:
yield [1]*k
else:
for first in [0,1]:
for sub in NPickK(bits-1,k-first):
yield [first]+sub
#生成实际可用的模板,比如bit=7
#那么会生成NPickK(6,3)和NPickK(6,6)的模板,然后最后一位补零
def generate_Mask(bit):
for mask_bit in range(3,bit,3):
for mask in NPickK(bit-1,mask_bit):
yield mask+[0]
#判断模板内是不是同一个数
def mask_is_same_number(strlist,mask):
num = [strlist[x] for x in range(len(mask)) if mask[x]==1]
return len(set(num)) == 1
#计算根据模板替换后质数的个数
def count_prime(strlist,mask):
counter = 0;
for dig in range(0+(mask[0]==1),10):
strlist = [str(dig) if mask[x]==1 else strlist[x]
for x in range(len(mask))]
counter += PrimeQ(int(''.join(strlist)))
return counter
#测试这个数是否有符合条件
def template_test(n):
strlist = list(str(n))
for mask in generate_Mask(len(strlist)):
if mask_is_same_number(strlist,mask):
if count_prime(strlist,mask) >= 8:
return True
return False
#main
num = 1000
while True:
#是否是1,3,7,9结尾
if not mod(num,10) in [1,3,7,9]:
pass
#是不是有超过3个的0,1,2
elif not (list(str(num)).count('0')>=3 or \
list(str(num)).count('1')>=3 or \
list(str(num)).count('2')>=3):
pass
elif not PrimeQ(num):
pass
elif not template_test(num):
pass
else:
print num;
break
num += 1
Problem 52:Permuted multiples
It can be seen that the number, 125874, and its double, 251748, contain exactly the same digits, but in a different order.
Find the smallest positive integer, x, such that 2x, 3x, 4x, 5x, and 6x, contain the same digits.
翻译:
125874和它的二倍,251748, 包含着同样的数字,只是顺序不同。
找出最小的正整数x,使得 2x, 3x, 4x, 5x, 和6x都包含同样的数字。
其实这道题不用编程我就知道答案了,如果了解1/7到6/7的循环节的性质的同学也应该一眼能看出来。。
如果真要编程,那么两个优化条件,第一,这个数假设是n位,那么这个数必然小于\(\dfrac{10^n}{6}\),其次,这个数必然能被三整除,因为这个数的3倍和这个所用的数字相同;所以对于n位数,我们每次搜索只要从\(10^{n-1}+2\)开始到\(\dfrac{10^n}{6}\),步进为3,就可以了;
Code:Python
def sortchar(n):
L = list(str(n))
L.sort()
return L
def QQ(n):
if sortchar(n)==\
sortchar(2*n)==\
sortchar(3*n)==\
sortchar(4*n)==\
sortchar(5*n)==\
sortchar(6*n):
return True
return False
bit = 3
k = 102
while True:
if QQ(k):
print k
break
k += 3
if k*6 > 10**bit:
k = 10**bit+2
bit += 1
Problem 53:Combinatoric selections
There are exactly ten ways of selecting three from five, 12345:
123, 124, 125, 134, 135, 145, 234, 235, 245, and 345
In combinatorics, we use the notation, \(^5C_3=10\).
In general,
\(^nC_r=\dfrac{n!}{r!(n-r)!}\),where r ≤ n, n! = n×(n−1)×…×3×2×1, and 0! = 1.
It is not until n = 23, that a value exceeds one-million: \(^{23}C_{10}= 1144066\) .
How many, not necessarily distinct, values of \(^nC_r\), for 1 ≤ n ≤ 100, are greater than one-million?
翻译:
从五个数12345中选出三个数一共有十种方法:
123, 124, 125, 134, 135, 145, 234, 235, 245, and 345
在组合数学中我们用 \(^5C_3=10\)来表示.
概括来说:
\(^nC_r=\dfrac{n!}{r!(n-r)!}\),其中 r ≤ n, n! = n×(n−1)×…×3×2×1, 并且0! = 1.
n = 23时产生第一个超过一百万的数:\(^{23}C_{10}= 1144066\) .
对于\(^nC_r\), 1 ≤ n ≤ 100,有多少超过100万的值?包括重复的在内。
这道题应该不会有人想不开到直接去算阶乘吧。。
如果要计算\(^nC_r\),我们可以由下式递推求解出来【Mathematica一行秒杀的问题。。】:
\(\dfrac{^nC_{r+1}}{^nC_r}=\dfrac{n-r}{r+1}\)
只要知道\(^nC_1=n\)就可以了;
其次,我们知道对于\(^nC_r\)它是在\(r=\lfloor \dfrac{n}{2}\rfloor\)的时候取得最大值,而且还有\(^nC_r=^nC_{n-r}\);
所以只要固定n,然后递归求解出哪个r可以使得\(^nC_r>1000000\),就可以马上知道对于n,有多少个r可以使得\(^nC_r>1000000\);
这个代码计算结果只要0.1s不到
Code:Python
counter = 0;
for n in range(23,101):
d = n;
r = 1;
while d < 1000000 and r <= int(n/2):
d = d * (n-r)/(r+1)
r += 1
counter += n-2*r+1
print counter
Problem 54:Poker hands
In the card game poker, a hand consists of five cards and are ranked, from lowest to highest, in the following way:
- High Card: Highest value card.
- One Pair: Two cards of the same value.
- Two Pairs: Two different pairs.
- Three of a Kind: Three cards of the same value.
- Straight: All cards are consecutive values.
- Flush: All cards of the same suit.
- Full House: Three of a kind and a pair.
- Four of a Kind: Four cards of the same value.
- Straight Flush: All cards are consecutive values of same suit.
- Royal Flush: Ten, Jack, Queen, King, Ace, in same suit.
The cards are valued in the order:
2, 3, 4, 5, 6, 7, 8, 9, 10, Jack, Queen, King, Ace.If two players have the same ranked hands then the rank made up of the highest value wins; for example, a pair of eights beats a pair of fives (see example 1 below). But if two ranks tie, for example, both players have a pair of queens, then highest cards in each hand are compared (see example 4 below); if the highest cards tie then the next highest cards are compared, and so on.
Consider the following five hands dealt to two players:
Hand Player 1 Player 2 Winner 1 5H 5C 6S 7S KD Pair of Fives2C 3S 8S 8D TD Pair of EightsPlayer 2 2 5D 8C 9S JS AC Highest card Ace2C 5C 7D 8S QH Highest card QueenPlayer 1 3 2D 9C AS AH AC Three Aces3D 6D 7D TD QD Flush with DiamondsPlayer 2 4 4D 6S 9H QH QC Pair of Queens
Highest card Nine3D 6D 7H QD QS Pair of Queens
Highest card SevenPlayer 1 5 2H 2D 4C 4D 4S Full House
With Three Fours3C 3D 3S 9S 9D Full House
with Three ThreesPlayer 1 The file, poker.txt, contains one-thousand random hands dealt to two players. Each line of the file contains ten cards (separated by a single space): the first five are Player 1’s cards and the last five are Player 2’s cards. You can assume that all hands are valid (no invalid characters or repeated cards), each player’s hand is in no specific order, and in each hand there is a clear winner.
How many hands does Player 1 win?
翻译:
在扑克游戏中,一局牌由五张牌组成,组成的牌的大小由低向高如下:
- High Card: 最高值的牌.
- One Pair: 两张面值一样的牌.
- Two Pairs: 两个值不同的One Pair.
- Three of a Kind: 三张面值一样的牌.
- Straight: 所有的牌面值为连续数值.
- Flush: 所有的牌花色相同.
- Full House: Three of a Kind 加一个One Pair.
- Four of a Kind: 四张牌面值相同.
- Straight Flush: 所有的牌花色相同并且为连续数值.
- Royal Flush: 10,J,Q,K和A,并且为相同花色。
牌的面值大小排序如下:
2, 3, 4, 5, 6, 7, 8, 9, 10, Jack, Queen, King, Ace.
如果两个玩家的牌具有同样的排序(上面介绍的几种),那么他们牌的大小由手中最大的牌决定。例如,一对8比一对5大(见下面例一);但是如果两个玩家都用一对Q,那么他们手中最大的牌就用来比较大小(见下面例四);如果他们最高面值的牌也相等,那么就用次高面值的牌比较,以此类推。
考虑下面的几个例子:
| 局 | 玩家 1 |
玩家 2 |
胜利者 |
| 1 | 5H 5C 6S 7S KD
一对5
|
2C 3S 8S 8D TD
一对8
|
玩家 2 |
| 2 | 5D 8C 9S JS AC
最大面值牌A
|
2C 5C 7D 8S QH
最大面值牌Q
|
玩家 1 |
| 3 | 2D 9C AS AH AC
三个A
|
3D 6D 7D TD QD
方片Flush
|
玩家 2 |
| 4 | 4D 6S 9H QH QC
一对Q
最大牌9 |
3D 6D 7H QD QS
一对Q
最大牌7 |
玩家 1 |
| 5 | 2H 2D 4C 4D 4S
三个4的Full House
|
3C 3D 3S 9S 9D
三个3的Full House
|
玩家 1 |
文件 poker.txt 包含一千局随机牌。每一行包含十张牌(用空格分隔);前五张是玩家1的牌,后五张是玩家2的牌。 所有的牌都是合理的(没有非法字符或者重复的牌)。每个玩家的牌没有顺序,并且每一局都有明确的输赢。
其中玩家1能赢多少局?
这种题长着就一脸没什么好优化的样子,就是死算。。
下面这个代码写的略挫,但是懒得改了。。我看官方论坛上别人的代码也是各种“disgusting”,哈哈。。
其实也是因为各种牌之间没什么规律性,很难合并讨论。。如果有谁可以写出很“优雅”的代码解决这道题,请务必告知我一声!!反正我的思路就是对每一种牌型进行分分级,然后同级别的比后面的牌就是了;
总之如很多人评价一样,EP上这道题not a nice problem
Code:Mathematica
PokeInfo = Import["poker.txt", "Table"];
GetWinner[game_] := Block[{p1p, p2p, p1c, p2c, lv1, lv2},
(*替换成数字,并排序*)
p1p = ToExpression[(StringTake[#, 1] & /@ game[[1 ;; 5]]) /.
{"A" ->14, "K" -> 13, "Q" -> 12, "J" -> 11, "T" -> 10}] // Sort;
p2p = ToExpression[(StringTake[#, 1] & /@ game[[6 ;; 10]]) /.
{"A" -> 14, "K" -> 13, "Q" -> 12,"J" -> 11, "T" -> 10}] // Sort;
(*分别获取玩家的牌*)
p1c = StringTake[#, {2}] & /@ game[[1 ;; 5]];
p2c = StringTake[#, {2}] & /@ game[[6 ;; 10]];
(*获得玩家的牌的类型*)
lv1 = GetLevel[p1p, p1c];
lv2 = GetLevel[p2p, p2c];
WHOWIN[lv1, lv2]]
GetLevel[p_, c_] := Block[{},
Which[
(*等级1000,同花顺*)
Length@Union@c == 1 && Differences[p] === {1, 1, 1, 1},{100,Reverse[p]},
(*等级99,四带一*)
Sort[Tally[p][[All, 2]]] === {1,4},
{99, {Select[Tally[p], #[[2]] == 4 &][[1, 1]],
Select[Tally[p], #[[2]] == 1 &][[1, 1]]}},
(*等级98,三带二*)
Sort[Tally[p][[All, 2]]] === {2,3},
{98, {Select[Tally[p], #[[2]] == 3 &][[1, 1]],
Select[Tally[p], #[[2]] == 2 &][[1, 1]]}},
(*等级97,一色*)
Length@Union@c == 1 , {97, Reverse[p]},
(*等级96,一条龙*)
Differences[p] === {1, 1, 1, 1}, {96, Reverse[p]},
(*等级95,三张一样*)
Sort[Tally[p][[All, 2]]] === {1, 1,3},{95, {Select[Tally[p], #[[2]] == 3 &][[1, 1]],
Select[Tally[p], #[[2]] == 1 &][[All, 1]] // Sort // Reverse} //Flatten},
(*等级94,两对*)
Sort[Tally[p][[All, 2]]] === {1, 2, 2},
{94, {Select[Tally[p], (#[[2]] == 2 &)][[All, 1]]//Sort//Reverse,
Select[Tally[p], #[[2]] == 1 &][[1, 1]]} // Flatten},
(*等级93,一对*)
Sort[Tally[p][[All, 2]]] === {1, 1, 1, 2},
{93, {Select[Tally[p], (#[[2]] == 2 &)][[All, 1]],
Select[Tally[p], #[[2]] == 1 &][[All, 1]] // Sort // Reverse} //Flatten},
(*啥都没有,等级为最大那张牌的点*)
True, {Max[p], Reverse[p]}]
]
(*判断胜负*)
WHOWIN[v1_, v2_] := Block[{},
Which[v1[[1]] > v2[[1]], 1,
v1[[1]] < v2[[1]], 2,
v1[[2, 1]] > v2[[2, 1]], 1,
v1[[2, 1]] < v2[[2, 1]], 2,
v1[[2, 2]] > v2[[2, 2]], 1,
v1[[2, 2]] < v2[[2, 2]], 2,
v1[[2, 3]] > v2[[2, 3]], 1,
v1[[2, 3]] < v2[[2, 3]], 2,
v1[[2, 4]] > v2[[2, 4]], 1,
v1[[2, 4]] < v2[[2, 4]], 2,
v1[[2, 5]] > v2[[2, 5]], 1,
v1[[2, 5]] < v2[[2, 5]], 2,
True, 0
]]
(*计算A胜了多少场*)
Select[PokeInfo, GetWinner[#] == 1 &] // Length
Problem 55:Lychrel numbers
If we take 47, reverse and add, 47 + 74 = 121, which is palindromic.
Not all numbers produce palindromes so quickly. For example,
349 + 943 = 1292,
1292 + 2921 = 4213
4213 + 3124 = 7337That is, 349 took three iterations to arrive at a palindrome.
Although no one has proved it yet, it is thought that some numbers, like 196, never produce a palindrome. A number that never forms a palindrome through the reverse and add process is called a Lychrel number. Due to the theoretical nature of these numbers, and for the purpose of this problem, we shall assume that a number is Lychrel until proven otherwise. In addition you are given that for every number below ten-thousand, it will either (i) become a palindrome in less than fifty iterations, or, (ii) no one, with all the computing power that exists, has managed so far to map it to a palindrome. In fact, 10677 is the first number to be shown to require over fifty iterations before producing a palindrome: 4668731596684224866951378664 (53 iterations, 28-digits).
Surprisingly, there are palindromic numbers that are themselves Lychrel numbers; the first example is 4994.
How many Lychrel numbers are there below ten-thousand?
NOTE: Wording was modified slightly on 24 April 2007 to emphasise the theoretical nature of Lychrel numbers.
翻译:
我们将47与它的逆转相加,47 + 74 = 121, 可以得到一个回文。
并不是所有数都能这么快产生回文,例如:
349 + 943 = 1292,
1292 + 2921 = 4213
4213 + 3124 = 7337
也就是说349需要三次迭代才能产生一个回文。
虽然还没有被证明,人们认为一些数字永远不会产生回文,例如196。那些永远不能通过上面的方法(逆转然后相加)产生回文的数字叫做Lychrel数。因为这些数字的理论本质,同时也为了这道题,我们认为一个数如果不能被证明的不是Lychrel数的话,那么它就是Lychre数。此外,对于每个一万以下的数字,你还有以下已知条件:这个数如果不能在50次迭代以内得到一个回文,那么就算用尽现有的所有运算能力也永远不会得到。10677是第一个需要50次以上迭代得到回文的数,它可以通过53次迭代得到一个28位的回文:4668731596684224866951378664。
令人惊奇的是,有一些回文数本身也是Lychrel数,第一个例子是4994。
10000以下一共有多少个Lychrel数?
这道题暴解没什么问题,毕竟数量级很小,而且每个数最多迭代50次嘛,所以python代码只要0.6秒就可以完成了;
如果参考以前的某道题,记录下每个数变成回文数所需要的数据长度的话,确实可以优化,但是实际上对于0.6秒就可以完成的题目而言,这点优化一点明显的效果也没有。。而且不优化代码可读性会好很多。。
Code:Python
def GetPalindromic(n):
return int(''.join(list(str(n))[::-1]))
def IsPalindromic(n):
return n == GetPalindromic(n)
def IsLychrel(n):
cc = 0
n = n + GetPalindromic(n)
while cc <= 50:
if IsPalindromic(n):
return False
n = n + GetPalindromic(n)
cc += 1
return True
result = filter(IsLychrel,range(10001))
print len(result)
Code:Mathematica
GetHW[x_] := FromDigits@Reverse@IntegerDigits[x]
IsNotHW[x_] := FromDigits@Reverse@IntegerDigits[x] != x
IsLychrel[t_] := Block[{x = t + GetHW[t], Result = True},
For[i = 1, i < = 50, i += 1,
If[IsNotHW[x], x = x + GetHW[x], Result = False; Break]];
Result]
Select[Range[1, 10000], IsLychrel] // Length
Problem 56:Powerful digit sum
A googol (10100) is a massive number: one followed by one-hundred zeros; 100100 is almost unimaginably large: one followed by two-hundred zeros. Despite their size, the sum of the digits in each number is only 1.
Considering natural numbers of the form, ab, where a, b < 100, what is the maximum digital sum?
翻译:
一个googol (10100)是一个巨大的数字:1后面跟着100个0;100100几乎是不可想象的大:1后面跟着200个0。它们虽然很大,但是它们的各位数之和却只有1。
考虑形如 ab 的数, 其中 a, b < 100,最大的各位和是多少?
这种题。。好像真没啥好办法,额。。Mma直接一行干翻!!
Python表示不甘示弱。。
Code:Mathematica
Max@Table[Total@IntegerDigits@(a^b), {a, 1, 99}, {b, 1, 99}]
Code:Python
print max([sum(map(int,list(str(a**b))))
for a in range(1,100)
for b in range(1,100)])
Problem 57:Square root convergents
It is possible to show that the square root of two can be expressed as an infinite continued fraction.
\(\sqrt{2}=1+\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2+…}}}=1.414213…\)
By expanding this for the first four iterations, we get:
1 + \(\dfrac{1}{2}\) = 3/2 = 1.5
1 + \(\dfrac{1}{2+\dfrac{1}{2}}\) = 7/5 = 1.4
1 + \(\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2}}}\)= 17/12 = 1.41666…
1 + \(\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2}}}}\) = 41/29 = 1.41379…The next three expansions are 99/70, 239/169, and 577/408, but the eighth expansion, 1393/985, is the first example where the number of digits in the numerator exceeds the number of digits in the denominator.
In the first one-thousand expansions, how many fractions contain a numerator with more digits than denominator?
翻译:
2的平方根可以被表示为无限延伸的分数:
\(\sqrt{2}=1+\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2+…}}}=1.414213…\)
将其前四次迭代展开,我们得到:
1 + \(\dfrac{1}{2}\) = 3/2 = 1.5
1 + \(\dfrac{1}{2+\dfrac{1}{2}}\) = 7/5 = 1.4
1 + \(\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2}}}\)= 17/12 = 1.41666…
1 + \(\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2+\dfrac{1}{2}}}}\) = 41/29 = 1.41379…
接下来三次迭代的展开是99/70, 239/169, and 577/408, 但是第八次迭代的展开, 1393/985, 是第一个分子的位数超过分母的位数的例子。
在前1000次迭代的展开中,有多少个的分子位数超过分母位数?
突然冒出一道这么简单的题目。。
前一个数假设是\(\dfrac{b}{a}\),那么迭代后的下一个数就是\(1+\dfrac{1}{1+\dfrac{b}{a}}=\dfrac{2a+b}{a+b}\);
唯一要感慨一下的就是Mma里面和Python里面的交换两个数的那种方法实在太简洁了!!
Code:Python
a = 2
b = 3
counter = 0
for i in range(1,1001):
a,b = b+a,2*a+b
if len(str(b)) > len(str(a)):
counter += 1
print counter
Code:Mathematica
Select[NestList[{2 #[[2]] + #[[1]], #[[2]] + #[[1]]} &, {3, 2}, 1000],
Length[IntegerDigits[#[[1]]]] > Length[IntegerDigits[#[[2]]]] &] // Length
Problem 58:Spiral primes
Starting with 1 and spiralling anticlockwise in the following way, a square spiral with side length 7 is formed.
37 36 35 34 33 32 31
38 17 16 15 14 13 30
39 18 5 4 3 12 29
40 19 6 1 2 11 28
41 20 7 8 9 10 27
42 21 22 23 24 25 26
43 44 45 46 47 48 49It is interesting to note that the odd squares lie along the bottom right diagonal, but what is more interesting is that 8 out of the 13 numbers lying along both diagonals are prime; that is, a ratio of 8/13 ≈ 62%.
If one complete new layer is wrapped around the spiral above, a square spiral with side length 9 will be formed. If this process is continued, what is the side length of the square spiral for which the ratio of primes along both diagonals first falls below 10%?
翻译:
从1开始逆时针旋转,可以得到一个边长为7的螺旋正方形。
37 36 35 34 33 32 31
38 17 16 15 14 13 30
39 18 5 4 3 12 29
40 19 6 1 2 11 28
41 20 7 8 9 10 27
42 21 22 23 24 25 26
43 44 45 46 47 48 49
有趣的是奇数的平方数都处于右下对角线上。更有趣的是,对角线上的13个数字中有8个质数,其百分比是8/13 ≈ 62%。
如果在上面的螺旋正方形上再加一层,可以得到一个边长为9的螺旋正方形。如果这个过程继续,到螺旋正方形的边长为多少时,对角线上的质数百分比第一次降到10%以下?
这道题没什么好说的,和之前第28题的思路差不多,但是居然让我震惊的是!!我居然一直没发现我这道题以前的判断质数的函数PrimeQ是如此的低效!!虽然思路一样,但是应该把range改成xrange!!这样速度可以快上一倍啊!!
Code:Python
def PrimeQ(n):
if n <= 1:
return False
for i in xrange(2,int(n**0.5+1)):
if n%i == 0:
return False;
return True;
k = 1
dif = 2
prime_counter = 0
while True:
k += dif * 4
dif += 2
prime_counter += PrimeQ(k+dif)
prime_counter += PrimeQ(k+2*dif)
prime_counter += PrimeQ(k+3*dif)
if prime_counter*10<(2*dif+1):
print dif+1
break
Problem 59:XOR decryption
Each character on a computer is assigned a unique code and the preferred standard is ASCII (American Standard Code for Information Interchange). For example, uppercase A = 65, asterisk (*) = 42, and lowercase k = 107.
A modern encryption method is to take a text file, convert the bytes to ASCII, then XOR each byte with a given value, taken from a secret key. The advantage with the XOR function is that using the same encryption key on the cipher text, restores the plain text; for example, 65 XOR 42 = 107, then 107 XOR 42 = 65.
For unbreakable encryption, the key is the same length as the plain text message, and the key is made up of random bytes. The user would keep the encrypted message and the encryption key in different locations, and without both “halves”, it is impossible to decrypt the message.
Unfortunately, this method is impractical for most users, so the modified method is to use a password as a key. If the password is shorter than the message, which is likely, the key is repeated cyclically throughout the message. The balance for this method is using a sufficiently long password key for security, but short enough to be memorable.
Your task has been made easy, as the encryption key consists of three lower case characters. Using cipher1.txt (right click and ‘Save Link/Target As…’), a file containing the encrypted ASCII codes, and the knowledge that the plain text must contain common English words, decrypt the message and find the sum of the ASCII values in the original text.
翻译:
电脑上的每个字符都有一个唯一编码,通用的标准是ASCII (American Standard Code for Information Interchange 美国信息交换标准编码)。例如大写A = 65, 星号(*) = 42,小写k = 107。
一种现代加密方法是用一个密钥中的给定值,与一个文本文件中字符的ASCII值进行异或。使用异或方法的好处是对密文使用同样的加密密钥可以得到加密前的内容。例如,65 XOR 42 = 107, 然后 107 XOR 42 = 65。
对于不可攻破的加密,密钥的长度与明文信息的长度是一样的,而且密钥是由随机的字节组成的。用户将加密信息和加密密钥保存在不同地方,只有在两部分都得到的情况下,信息才能被解密。
不幸的是,这种方法对于大部分用户来说是不实用的。所以一种修改后的方案是使用一个密码作为密钥。如果密码比信息短,那么就将其不断循环直到明文的长度。平衡点在于密码要足够长来保证安全性,但是又要足够短使用户能够记得。
你的任务很简单,因为加密密钥是由三个小写字母组成的。文件 cipher1.txt (右键另存为)包含了加密后的ASCII码,并且已知明文是由常用英语单词组成。使用该文件来解密信息,然后算出明文中字符的ASCII码之和。
看到这道题我马上想起我以前写过的这篇博文。。。还有这一篇维基娘。。
所以我解答也是利用的以前的结论,还是把以前的图给拿过来吧:
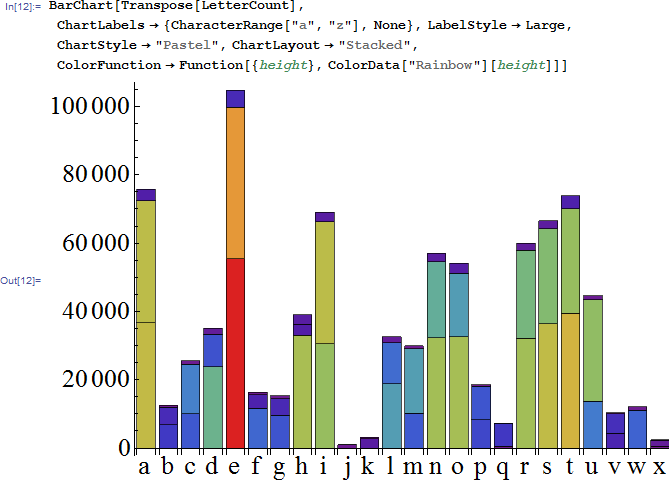
也就是说,一般文章里面出现频数最多的无非是a,e,i,s这些,所以呢,作为判断译码结果准确率的条件,我们可以统计这些文字里面这些字母出现的频数就可以了;
当然还有别的调教方法,比如说根据这幅,还可以统计the出现的频数:
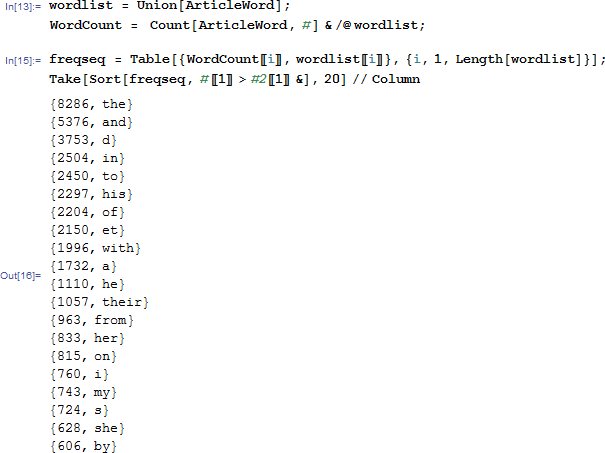
最后算出来加密字符是“God”;经过我的实验,事实上提取the的效果比提取元音那种方法要好很多。。。因为元音里面,最高的组合可以出现294个,第二名270+,所以你也不好说你找到的第一个答案一定是标准答案;但是寻找the的个数的方法,第一名20个,第二名才5个,所以这个就靠谱多了~
Code:Mathematica
(*读取文件,转为数字*)
cipher = ToExpression@StringSplit[ToLowerCase@Import["cipher1.txt"], ","];
(*获得加密原文*)
decodetext[key_, ci_] := Block[{test, result},
(*循环密钥使之与密文等长*)
test = Table[key[[Mod[i - 1, 3] + 1]], {i, 1, Length[ci]}];
result = MapThread[BitXor, {ci, test}]]
(*译码,key是密钥,ci是密文,返回a,e,i,s的词频数*)
decode[key_, ci_] := Total[
Count[decodetext[key, ci], #]&/@(ToCharacterCode/@{"e", "a", "i", "s"}//Flatten)]
(*测试所有加密方案*)
ParallelTable[{{a, b, c}, decode[{a, b, c}, cipher]},
{a, 97, 122}, {b, 97, 122}, {c, 97, 122}];
(*找出加密方案中最佳的那个*)
(Reverse@SortBy[Flatten[%, 2], Last])//First
(*获得原文全部ASCII码之和*)
decodetext[First@%, cipher] // Total
(*统计the*)
decode2[key_, ci_]:=StringCount[FromCharacterCode@decodetext[key, ci], "the"]
(*获取原文*)
decodetext[First@%, cipher]//FromCharacterCode
Problem 60:Prime pair sets
The primes 3, 7, 109, and 673, are quite remarkable. By taking any two primes and concatenating them in any order the result will always be prime. For example, taking 7 and 109, both 7109 and 1097 are prime. The sum of these four primes, 792, represents the lowest sum for a set of four primes with this property.
Find the lowest sum for a set of five primes for which any two primes concatenate to produce another prime.
翻译:
质数3, 7, 109, 和 673是值得注意的。将其中任意两个质数以任何顺序相连接产生的结果都是质数。例如,取7和109,连接而成的7109和1097都是质数。这四个质数的和是792,这也是满足这个性质的四个质数集合的最小总和。
找出满足这个性质的五个质数的集合中,集合数之和最小的。算出这个最小的和。
这道题我到最后还是没有真正解决,如果真有非常巧面的方法的话,那么这道题就是目前为止最难的一道了。。
这道题有两个难点,一个是,你无法像之前的题目那样计算出搜索的上限,第二,你就算找到一个解了,你要怎么证明这个解是最小的?!
关于第一个,一般常用的方法就是逐步向上搜索,比如对于五元数组{i,j,k,m,n},我们令i>j.k>m>n,搜索过程中逐渐
增加i,然后j从4取到i-1,k从3取到j-1,m从2取到k-1,n从1取到m-1这样,这样就可以在不预设上限的情况下找到解;
但是找到了问题来了,假设我们找到一组解,{i1,j1,k1,m1,n1},怎么样才可以保证这组解是最小的呢?那么我们必须一直搜索i到i1+j1+k1+m1+n1为止,这将是很恐怖的计算,因为我们知道随着i的增加,计算的数量级会以o(n5)的数量增多;
但是我除了暴力解决实在找不到什么好方法,用Mathematica和Python写了一遍,十几分钟才出结果;无奈只能动用C++这个大杀器!!虽然下面这个代码在9秒算出结果;但————是——————根本不能算解决!!因为我是预设了一个上限,然后用筛选法预先找出全部质数,然后再暴解,找出第一个解,碰巧就是最小的那个解而已。。。
这道题如果在Mathematica里面我真想不到有什么函数可以替换来快速解决这个算法(取代for里面套for);Python的话如果虽然可以生成质数表,然后将其转为set,这样判断一个数是不是in这个set的话可以大大提速(接近40倍),但是生成这个质数表的过程太慢了;因为假设你i的搜索上限设为1000,那么你的质数表就要保证达到999999这么大,如果是10000,那么就要达到99999999这么大,这个速度我测试了一下,太慢了。。。或许是我代码不好。。
而C++的话,想要快速判断一个数在不在质数表里面,不能像python用in,那么只好存下所有数,然后令质数索引结果为1。。。然后拼接两个整数,字符串方法比较慢,只好用log10这种纯数学方法了。。。
总之,这道题谁有好方法,欢迎留言讨论。。。
另外,为了让代码简洁,我用了递归,但是太不喜欢这个代码了,所以这个代码是算出一组解后,pause,你按个按键继续算,但是下一个会因为超出表的索引而溢出,我懒得改了。。。
Code:C++
#define T 100000000
int IsPrime[T] = {1};
int* primelist = NULL;
//初始化质数表
void init()
{
for(int i = 0;i < T;i++)
IsPrime[i] = 1;
IsPrime[0] = -1;
IsPrime[1] = -1;
}
//筛选法找质数
void Seive()
{
int counter = T-2;
for(int i = 2;i <= T/2;i++)
{
if(IsPrime[i] != 1)
continue;
int j = 2*i;
while(j < T)
{
if(IsPrime[j] == 1)
counter--;
IsPrime[j] = -1;
j += i;
}
}
primelist =new int[counter];
int cc = 0;
for(int i = 0;i < T;i++)
if(IsPrime[i] == 1)
primelist[cc++] = i;
}
//数字拼接,673+123=673123
int join(int a,int b)
{
int k = int(log10(double(a))+1);
return int(b*pow(10.0,k)+a);
}
//判断两个数连接起来后是不是质数
bool Judge(int i,int j)
{
return IsPrime[join(i,j)] == 1 && IsPrime[join(j,i)] == 1;
}
//判断list里面最后一个数和前面每个数连接起来后都是质数
int JudgeList(int list[],int num)
{
for(int i = 0;i < num-1;i++)
if(!Judge(list[i],list[num-1]))
return 0;
return 1;
}
//递归求解,i是前一个数,idx是现在算到第几个数了
void figure(int i,int list[],int idx)
{
if(idx == 6)
{
for(int d = 0;d < 5;d++)
cout<<list[d]<<" ";
system("pause");
}
for(int j = i-1;j >= 5-idx;j--)
{
list[idx-1] = primelist[j];
if (!JudgeList(list,idx))
continue;
figure(j,list,idx+1);
}
}
int main(int argc,char* argv[])
{
init();
Seive();
int list[5];
for(int i = 4;i < T;i++)
{
list[0] = primelist[i];
figure(i,list,2);
}
return 0;
}
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

看起来好高端,啊哈哈
其实一点也不。。只是练练算法题和编程。。。防止头脑老化。。
真上进
爱好而已。。。将来找工作希望有点用。。
pe57:Count[NestList[{2 #2 + #, #2 + #} & @@ # &, {3, 2}, 1000], {a_, b_} /; IntegerLength@a > IntegerLength@b]
研读完您的留言代码,获益良多,学会了很多新函数和思想,非常感谢!
打扰了!, 关于PE51,我找到个11113,替换三个数之后得{11113, 19993, 22123, 31333, 41443, 77713, 81883, 88813}都是质数,一共刚好8个,,这样行不?
对于56**3,两个星号替换的数字必须一样
哈哈,,有道理,,看题不仔细
http://blog.dreamshire.com/project-euler-54-solution/ PE54这个写的真简洁
事隔这么久,不知道博主还看评论吗。。。关于第六十题,实际上可以转化成为图论中的分团问题,从而用Bron–Kerbosch算法求解,代码可以优雅直观很多,具体请参见的我的博文:https://www.cnblogs.com/metaquant/p/11881378.html
博主的解题思路都很精妙,点个赞。