K-Means++
之前在这里讲AP聚类算法的时候顺带提到了K-Means算法,但是就提到了K-Means算法有两个比较麻烦的弊端,一个是聚类的数目不能自动设置,而要人工设定。另外一个就是对迭代的初始点很敏感,初始点选的不好很容易得出错误的聚类结果来。
然后呢,前阵子无意中看到了K-Means算法的加强版,叫做K-Means++算法【维基请猛戳这里←】,这个算法解决了初始点敏感问题,额。。一定程度上把。。
根据维基上的说法,K-Means++这个算法步骤大概如下:
- 在已有的所有点中随机选取一个点,将其加入初始点。
- 对于所有的点,计算出他们的D值,D值就是每个点到距离他们最近的初始点的距离的平方。
- 对所有点选取下一个点加入初始点的集合,每个点被选取的概率正比于他们的D值。
- 如果初始点集合数目没有达到预定的数目,回到2,否则到5。
- 执行K-Means算法
这个算法为什么可以很好的解决K-Means算法的初值选择问题呢??我们考虑二维点集的聚类问题,K-Means算法是随便选择初始点,那么就会有一定的概率在一个Cluster内部出现两个或者更多的初始点,还有一种可能就是初始点出现在两个Cluster的正中间这种,反正就是会导致算法不是很有效,一个最常见的失败的聚类经常就是在某些地方把两类聚为一类,然后在另外一些地方把一类分为两类。但是呢,K-Means++算法可以很有效的避免这种状况,比如我在某一Cluster中间已经出现了一个初始点了,那么这个Cluster的点到这个初始点的距离就很小,平方后D值就更小了,所以这里面的点被选为下一个Cluster的概率就会很小。大部分情况下,K-Means++初始化完成之后每个Cluster就会有一个初始化点,这种时候我们就知道里聚类完成也差不多了。所以呢,K-Means++算法也可以很好地降低K-Means算法的迭代次数,换言之,就是算法的时间消耗。
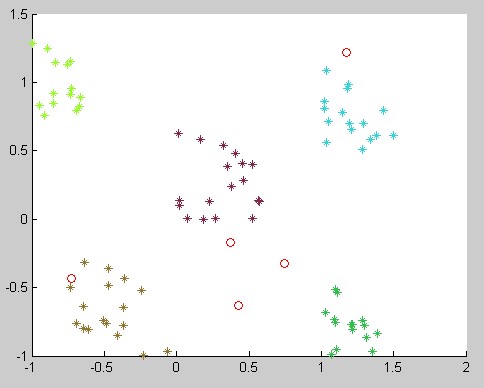
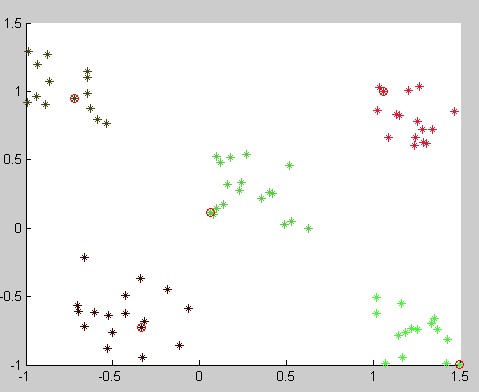 可以看出,K-Means++的效果很好,而K-Means那种初始化点让你对最后能否聚类表示很没信心。。
可以看出,K-Means++的效果很好,而K-Means那种初始化点让你对最后能否聚类表示很没信心。。
我之前再在这个算法的时候曾经产生过一个担心的问题,就是假设我某一个Cluster的点数远远大于另外一个Cluster,那假设我这个大数目的Cluster已经有一个初始点了,下一轮中虽然我这个大数目的Cluster的D值都很小,但是我的人数众多,那么会不会导致这个加起来的D值比其他的要大,或者差不多也行,这样下一个也有可能出现在这一个Cluster中,(我想D值是距离的平方就是为了一定程度上防止这个问题的吧。。)
然后我做了个实验研究了一下,发现这个担心其实没有太大的所谓,比如我选取了某个Cluster的数目是其他的20倍,这样确实会让很多初始点出现在这个大数目Cluster中,但是最后还是可以成功聚类的(或许这就要归功于K-Means算法吧。。)
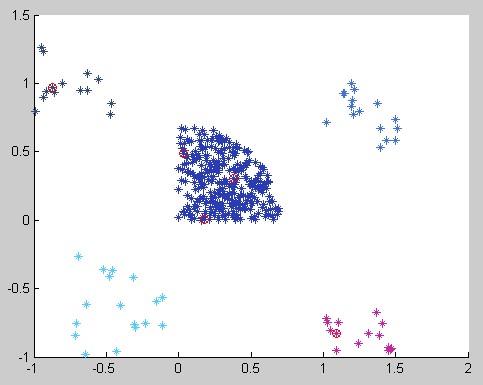
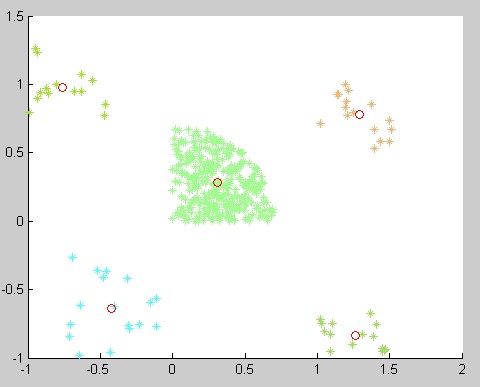 为了对比K-Means和K-Means++算法的优劣(额。。优劣自然不用说,应该说看看K-Means++比K-Means好多少。。)
为了对比K-Means和K-Means++算法的优劣(额。。优劣自然不用说,应该说看看K-Means++比K-Means好多少。。)
实验从两个角度思考,一个是聚类的正确率问题,另外一个是计算时间(或者说算法收敛的速度)。
正确率方面呢,首先比较难判断一次聚类的正确率是多少,是100%还好,如果不是,只有部分聚类正确,那么这个正确率要怎么算了,额,由于懒得考虑这个问题,我就直接把某次聚类的结果二值化,不是对就是错,然后对于同一组数据随机挑选初始点100次,聚类100次,100次内的实验正确次数就是这个算法对于这组数据的正确率。然后我用了100组数据来同时测试K-Means和K-Means++算法,正确率曲线如下:
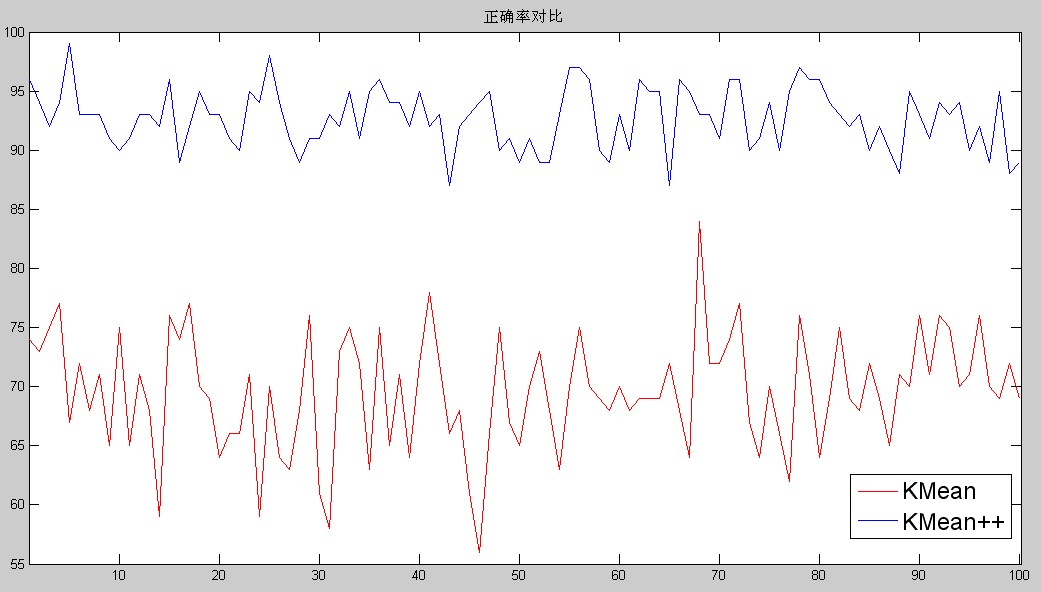 从上图中可以直接看的出来,K-Means++的聚类正确率要比K-Means好很多,除了大小的比较,我们还可以发现K-Means++的正确率的稳定性要远远高于K-Means算法。所以说在正确率上K-Means++完胜K-Means。
从上图中可以直接看的出来,K-Means++的聚类正确率要比K-Means好很多,除了大小的比较,我们还可以发现K-Means++的正确率的稳定性要远远高于K-Means算法。所以说在正确率上K-Means++完胜K-Means。
再来看看收敛速度问题。我在程序中设定的是如果三次迭代后分类结果没有变,那么就说明算法已经收敛了。我也是对每组数据做100此实验算出平均迭代次数,再用100组数据来对比,结果见下:
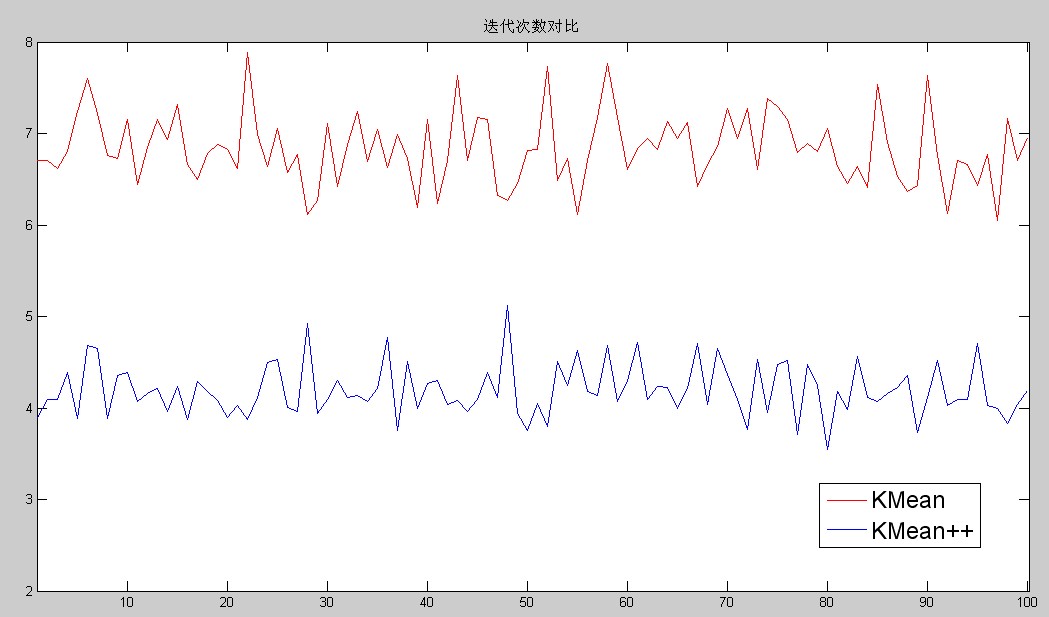 和预期想的完全一样,K-Means++的收敛速度要比K-Means的好很多。而且我们看到K-Means++大概在4次左右就完成迭代,而我之前说了,至少3次分类结果不变才算算法收敛,所以可以看出,K-Means++算法在一开始得出初始点的时候,基本就是一个Cluster一个初始点的那种。
和预期想的完全一样,K-Means++的收敛速度要比K-Means的好很多。而且我们看到K-Means++大概在4次左右就完成迭代,而我之前说了,至少3次分类结果不变才算算法收敛,所以可以看出,K-Means++算法在一开始得出初始点的时候,基本就是一个Cluster一个初始点的那种。
嗯,算法分析就到这里,下面是代码。
Code:
function k_mean()
clc;clear all;close all;
ClusterNum = 5;
ClusterSize = [15 16 14 17 18];
m_idx = zeros(1,sum(ClusterSize));
tt = [0 cumsum(ClusterSize)];
for i = 1 : ClusterNum
m_idx(tt(i)+1:tt(i+1)) = i * ones(1,ClusterSize(i));
end
Center = [1 -1
1 0.5
-1 0.75
-0.75 -1
0 0];
Radius = [0.5 0.6 0.55 0.8 0.7];
%初始化所有点
f = InitAllPoint(ClusterNum,ClusterSize,Center,Radius);
%随机选择起始迭代点
% InitPoint = RandomInitPoint(ClusterNum,f);
%k_mean++算法来选择起始点
InitPoint = InitByKMeanPlusPlus(ClusterNum,f);
% 画出初始化的分类图
DrawStandarCluster(ClusterNum,f,m_idx);
% 画出初始迭代的点
plot(InitPoint(:,1),InitPoint(:,2),'ro');
[idx center]= GetKMeanResult(InitPoint,f);
% 画出聚类结果
figure;
DrawStandarCluster(size(center,1),f,idx);
plot(center(:,1),center(:,2),'ro');
% 判断聚类是否正确
ClusterRight(ClusterSize,idx)
function InitPoint = InitByKMeanPlusPlus(ClusterNum,f)
InitPoint = zeros(ClusterNum,2);
%随机选一个点作出初始种子
InitPoint(1,:) = f(randint(1,1,[1,size(f,1)]),:);
for i = 2 : ClusterNum
D = zeros(1,size(f,1));
for j = 1 : size(f,1)
temp_dis = zeros(1,i-1);
for k = 1 : i-1
temp_dis(k) = Distance(f(j,:),InitPoint(k,:));
end
D(j) = min(temp_dis)^2;
end
D2 = cumsum(D);
D2 = D2 / D2(end);
r = rand();
iii = find(D2>=r);
InitPoint(i,:) = f(iii(1),:);
end
%%判断聚类结果是否正确
function IsRight = ClusterRight(ClusterSize,idx)
IsRight = 1;
temp = [0 cumsum(ClusterSize)];
for i = 1 : size(ClusterSize,2)
tt = idx(temp(i)+1:temp(i+1));
if(length(tt(find(tt~= mode(tt)))) == 0)
%没有某一类个数为0
if(length(idx(find(idx ~= mode(tt)))) == length(idx) - length(tt))
continue;
else
IsRight = 0;
break;
end
else
IsRight = 0;
break;
end
end
%得到kmean算法聚类的结果和中心
function [Cur_idx InitPoint]= GetKMeanResult(InitPoint,f)
result = zeros(size(f,1),2);
Last_idx = FindNearest(InitPoint,f);
Cur_idx = Last_idx;
same_time = 0;
for iter = 1 : 100
InitPoint = UpdateCenter(f,Last_idx,size(InitPoint,1));
Last_idx = Cur_idx;
Cur_idx = FindNearest(InitPoint,f);
if(sum(abs(Last_idx - Cur_idx)) == 0)
same_time = same_time+1;
else
same_time = 0;
end
if(same_time == 3)
% iter
break;
end
end
% Cur_idx'
% InitPoint
% figure;
% DrawStandarCluster(size(InitPoint,1),f,Cur_idx);
% plot(InitPoint(:,1),InitPoint(:,2),'ro');
%更新中心位置
function Center = UpdateCenter(f,idx,ClusterNum)
Center = zeros(ClusterNum,2);
for i = 1 : ClusterNum
clu = f(find(idx == i),:);
Center(i,:) = sum(clu,1)/size(clu,1);
end
%寻找每个点最近的那个中心的位置
function idx = FindNearest(CenterSet,f)
idx = zeros(size(f,1),1);
for i = 1 : length(idx)
dis_set = zeros(1,size(CenterSet,1));
for j = 1 : size(CenterSet,1)
dis_set(j) = Distance(CenterSet(j,:),f(i,:));
end
[m min_idx] = min(dis_set);
idx(i) = min_idx;
end
%随机找到初始迭代点
function p = RandomInitPoint(ClusterNum,f)
x_min = min(f(:,1));
x_max = max(f(:,1));
y_min = min(f(:,2));
y_max = max(f(:,2));
p = rand(ClusterNum,2);
p = p .* [ones(ClusterNum,1)*(x_max-x_min) ...
ones(ClusterNum,1)*(y_max-y_min)] +...
[ones(ClusterNum,1)*x_min ...
ones(ClusterNum,1)*y_min];
%根据初始条件随即初始化所有点
function f = InitAllPoint(ClusterNum,ClusterSize,Center,Radius)
f = zeros(sum(ClusterSize),2);
g_idx = 1;
for i = 1 : ClusterNum
while(ClusterSize(i) ~= 0)
p = rand(1,2);
while(norm(p) > 1)
p = rand(1,2);
end
f(g_idx,:) = p*Radius(i) + Center(i,:);
g_idx = g_idx + 1;
ClusterSize(i) = ClusterSize(i) - 1;
end
end
%画出聚类结果
function DrawStandarCluster(ClusterNum,f,idx)
h = plot([],[]);
hold on;
for i = 1 : ClusterNum
col=rand(1,3);
set(h,'Color',col,'MarkerFaceColor',col);
temp = f(find(idx == i),:);
plot(temp(:,1),temp(:,2),'*','Color',col);
end
%计算距离
function dis = Distance(P1,P2)
dis = norm(P1 - P2);
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

博主,我在MATLAB中调用kmeans算法时有些问题啊,初始的聚类中心位置错了,我只能手动的给他位置,而且效果也只能说是一般[Idx,Ctrs,SumD,D] = kmeans(M1,2,’Start’,[225,200;300,400],’Distance’,’city’,’Options’,opts);如果没有手动给的初始值,那么应该在哪里修改呢?怎样才能修正呢?
kmeans本身就对初始值敏感,所以才会有kmeans++来改进;所以你可以写个函数用kmeans++算法生成初始值,然后传入给’start’参数;这样其实就变成kmeans++算法了:)
那这个初始值必须要手动输入吗?能不能写一个程序直接赋值?
可以的啊,就是写一个函数,如本文代码中的InitByKMeanPlusPlus,然后把返回值传进kmeans中
哦,好的,谢谢啊,我会尝试一下的,能不能留一个联系方式,邮箱QQ什么的都可以